社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
上一篇讲了Geatpy的库函数和数据结构https://blog.csdn.net/qq_33353186/article/details/82020507
熟悉了之后,我尝试编写一个编程模板解决一个约束优化问题:
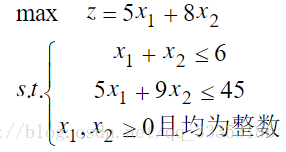
在这个问题里,我们很容易知道目标函数的最小值为0,而这是个目标函数最大化问题,因此,我们可以对不符合约束条件的解的目标函数值设为0。而且不需要写罚函数了,直接把约束条件写在目标函数接口文件里即可。
编写目标函数接口文件:
""" aimfuc.py """
import numpy as np
# aim function
def aimfuc(variables):
x1 = variables[:, 0] # get x1
x2 = variables[:, 1] # get x2
f = 5 * x1 + 8 * x2
idx1 = np.where(x1 + x2 > 6)[0]
idx2 = np.where(5 * x1 + 9 * x2 > 45)[0]
f[idx1] = 0
f[idx2] = 0
return np.array([f]).T # 对结果进行转置,使目标函数值矩阵符合Geatpy数据结构
下面一步步来编写编程模板,以解决这个约束优化问题。
编写编程模板时一个要注意的地方是:调用目标函数时,传入的参数必须和目标函数的参数列表一致。
我们试一下一种改进的遗传算法,即不用遗传算法的经典流程,而是在进化过程中,先对父代进行交叉和变异产生子代,然后父代和子代直接合并成一个大的种群,再从这个大的种群中挑选50%的优秀个体存活下来。在下一次进化迭代中,这50%的个体继续沿用上面的流程进行交叉、变异、选择。
这种改进遗传算法的好处是具有很强的精英保留能力。可以使算法快速收敛,得到最优结果。
为了使模板函数能够用于更多的场景,能同时解决整数型和实数型控制变量的问题。于是编写编程模板如下:
""" templet.py """
# -*- coding: utf-8 -*-
import numpy as np
import geatpy as ga
import time
"""
输入参数:
AIM_M - 目标函数的地址,传入该函数前通常由AIM_M = __import__('目标函数名')语句得到
AIM_F : str - 目标函数名
PUN_M - 罚函数的地址,传入该函数前通常由PUN_M = __import__('罚函数名')语句得到
PUN_F : str - 罚函数名
FieldDR : array - 实际值种群区域描述器
[lb; (float) 指明每个变量使用的下界
ub] (float) 指明每个变量使用的上界
注:不需要考虑是否包含变量的边界值。在crtfld中已经将是否包含边界值进行了处理
本函数生成的矩阵的元素值在FieldDR的[下界, 上界)之间
problem : str - 表明是整数问题还是实数问题,'I'表示是整数问题,'R'表示是实数问题
maxormin int - 最小最大化标记,1表示目标函数最小化;-1表示目标函数最大化
MAXGEN : int - 最大遗传代数
NIND : int - 种群规模,即种群中包含多少个个体
SUBPOP : int - 子种群数量,即对一个种群划分多少个子种群
GGAP : float - 代沟,本模板中该参数为无用参数,仅为了兼容同类的其他模板而设
selectStyle : str - 指代所采用的低级选择算子的名称,如'rws'(轮盘赌选择算子)
recombinStyle: str - 指代所采用的低级重组算子的名称,如'xovsp'(单点交叉)
recopt : float - 交叉概率
pm : float - 重组概率
输出参数:
pop_trace : array - 种群进化记录器(进化追踪器),
第0列记录着各代种群最优个体的目标函数值
第1列记录着各代种群的适应度均值
第2列记录着各代种群最优个体的适应度值
var_trace : array - 变量记录器,记录着各代种群最优个体的变量值,每一列对应一个控制变量
times : float - 进化所用时间
"""
def templet(AIM_M, AIM_F, PUN_M, PUN_F, FieldDR, problem, maxormin, MAXGEN, NIND, SUBPOP, GGAP, selectStyle, recombinStyle, recopt, pm):
"""==========================初始化配置==========================="""
GGAP = 0.5 # 因为父子合并后选择50%的个体留到下一代,因此要将代沟设为0.5以维持种群规模
# 获取目标函数和罚函数
aimfuc = getattr(AIM_M, AIM_F) # 获得目标函数
if PUN_F is not None:
punishing = getattr(PUN_M, PUN_F) # 获得罚函数
NVAR = FieldDR.shape[1] # 得到控制变量的个数
# 定义进化记录器,初始值为nan
pop_trace = (np.zeros((MAXGEN ,2)) * np.nan)
# 定义变量记录器,记录控制变量值,初始值为nan
var_trace = (np.zeros((MAXGEN ,NVAR)) * np.nan)
"""=========================开始遗传算法进化======================="""
if problem == 'R':
Chrom = ga.crtrp(NIND, FieldDR) # 生成初始种群
elif problem == 'I':
Chrom = ga.crtip(NIND, FieldDR)
start_time = time.time() # 开始计时
# 开始进化!!
for gen in range(MAXGEN):
# 进行遗传算子,生成子代
SelCh=ga.recombin(recombinStyle, Chrom, recopt, SUBPOP) # 重组
if problem == 'R': # 若是实数型控制变量,则用mutbga进行变异
SelCh=ga.mutbga(SelCh,FieldDR, pm) # 变异
elif problem == 'I': # 若是整数型控制变量,则用mutint进行变异
SelCh=ga.mutint(SelCh, FieldDR, pm)
Chrom = np.vstack([Chrom, SelCh]) # 父子合并
ObjV = aimfuc(Chrom) # 求后代的目标函数值
pop_trace[gen,0] = np.sum(ObjV) / ObjV.shape[0] # 记录种群个体平均目标函数值
if maxormin == 1:
pop_trace[gen,1] = np.min(ObjV) # 记录当代目标函数的最优值
var_trace[gen,:] = Chrom[np.argmin(ObjV), :] # 记录当代最优的控制变量值
elif maxormin == -1:
pop_trace[gen,1] = np.max(ObjV)
var_trace[gen,:] = Chrom[np.argmax(ObjV), :] # 记录当代最优的控制变量值
# 最后对合并的种群进行适应度评价并选出一半个体留到下一代
FitnV = ga.ranking(maxormin * ObjV, None, SUBPOP)
if PUN_F is not None:
FitnV = punishing(Chrom, FitnV) # 调用罚函数
Chrom=ga.selecting(selectStyle, Chrom, FitnV, GGAP, SUBPOP) # 选择
end_time = time.time() # 结束计时
# 绘图
ga.trcplot(pop_trace, [['种群个体平均目标函数值', '种群最优个体目标函数值']])
if maxormin == 1:
best_gen = np.argmin(pop_trace[:, 1]) # 记录最优种群是在哪一代
print('最优的目标函数值为:'+ str(np.min(pop_trace[:, 1])))
elif maxormin == -1:
best_gen = np.argmax(pop_trace[:, 1]) # 记录最优种群是在哪一代
print('最优的目标函数值为:' + str(np.max(pop_trace[:, 1])))
print('最优的控制变量值为:')
for i in range(NVAR):
print(var_trace[best_gen, i])
print('最优的一代是第' + str(best_gen + 1) + '代')
times = end_time - start_time
print('时间已过'+ str(times) + '秒')
# 返回进化记录器、变量记录器以及执行时间
return [pop_trace, var_trace, times]
好了,现在该编程模板可以用于解决这类约束优化问题了。控制变量既可以是整数,也可以是实数。
下面编写执行脚本:
import numpy as np
import geatpy as ga
from aimfuc import aimfuc
from templet import templet # 导入自定义的编程模板
# 获取函数接口地址
AIM_M = __import__('aimfuc')
# 变量设置
x1 = [0, 100] # 自变量1的范围
x2 = [0, 100] # 自变量2的范围
b1 = [1, 1] # 自变量1是否包含下界
b2 = [1, 1] # 自变量2是否包含上界
ranges=np.vstack([x1, x2]).T # 生成自变量的范围矩阵
borders = np.vstack([b1, b2]).T # 生成自变量的边界矩阵
# 生成区域描述器
FieldDR = ga.crtfld(ranges, borders)
# 调用编程模板
[pop_trace, var_trace, times] = templet(AIM_M, 'aimfuc', None, None, FieldDR, problem = 'I', maxormin = -1, MAXGEN = 2000, NIND = 100, SUBPOP = 1, GGAP = 0.9, selectStyle = 'tour', recombinStyle = 'xovdp', recopt = 0.7, pm = 0.1)因为这道题的控制变量x1和x2的区间都是单侧的,因此我们设个大一点的区间以便搜索最优解。我们采用锦标赛选择算子,并设置最大进化代数为100,种群规模为100,使用两点交叉,交叉和变异概率分别是0.9和0.1。
运行结果如下:
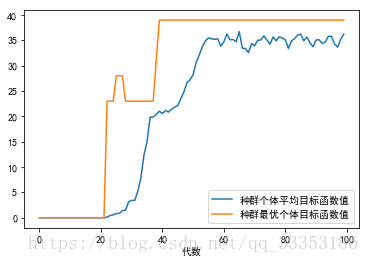
最优的目标函数值为:39.0
最优的控制变量值为:
3.0
3.0
最优的一代是第40代
时间已过0.11623454093933105秒
至此,我们知道了如何自定义编程模板实现遗传算法了。在Geatpy中,内置了好几种进化算法编程模板。详细源码可以参见https://github.com/geatpy-dev/geatpy/tree/master/geatpy/source-code/templets
使用Geatpy内置模板会使上面的例子变得更加简单,只需编写目标函数接口和执行脚本就可以了。比如上面的例子,使用Geatpy框架,真正只需几行代码便可以解决:
""" main.py """
import numpy as np
import geatpy as ga
# define aim function
def aimfuc(variables):
x1 = variables[:, 0] # get x1
x2 = variables[:, 1] # get x2
f = 5 * x1 + 8 * x2
idx1 = np.where(x1 + x2 > 6)[0]
idx2 = np.where(5 * x1 + 9 * x2 > 45)[0]
f[idx1] = 0; f[idx2] = 0
return np.array([f]).T # 对结果进行转置,使目标函数值矩阵符合Geatpy数据结构
# 获取目标函数地址
AIM_M = __import__('main')
# 变量设置
x1 = [0, 100] # 自变量1的范围
x2 = [0, 100] # 自变量2的范围
b1 = [1, 1] # 自变量1是否包含下界
b2 = [1, 1] # 自变量2是否包含上界
ranges = np.vstack([x1, x2]).T # 生成自变量的范围矩阵
borders = np.vstack([b1, b2]).T # 生成自变量的边界矩阵
FieldDR = ga.crtfld(ranges, borders) # 生成区域描述器
# 调用Geatpy内置编程模板
[pop_trace, var_trace, times] = ga.sga_new_real_templet(AIM_M, 'aimfuc', None, None, FieldDR, problem = 'I', maxormin = -1, MAXGEN = 100, NIND = 100, SUBPOP = 1, GGAP = 0.9, selectStyle = 'tour', recombinStyle = 'xovdp', recopt = 0.7, pm = 0.1)在后面的版本中,Geatpy将不断丰富和改进编程模板,以Geatpy的算法性能。比如添加MOEA/D多目标优化编程模板等。有相关想法的也可以email:jazzbin@geatpy.com。
更多教程可以参见官网http://www.geatpy.com (repairing),以及参见Geatpy的源码和demo示例:https://github.com/geatpy-dev/geatpy/tree/master/geatpy/demo 你将有更多的收获。
在下一篇,我们将讲述如何使用Geatpy解决一些实际的有趣问题。
https://blog.csdn.net/qq_33353186/article/details/82047692 欢迎继续跟进,谢谢大家!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
