社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
k-means算法有个很大的缺点,就是对孤立点敏感性太高,孤立点即是脱离群众的点,与众不同的点,即在显示中与其他点不是抱在一团的点。
为了体现两者的不同,我特意温习了一下知识,在构造初始点的时候,自己定义加入了几个孤立点,使用k-means算法跑的效果如下:
一开始的所有点:(可以看出其他点是混在一起有许多分类的)

使用k-means算法运行,定义3个中心点:

可以看到,此时的确是被分成了三类,只不过两个孤立点算在了一类
那么试一下k中心点算法,初始:
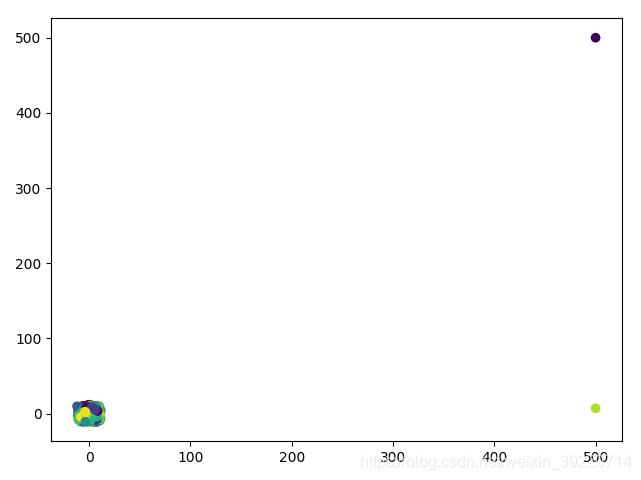
运算之后:

就这么简单,就验证了k中心点算法的优越之处
1.算法理论
1.1 聚类
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。
简单的说,就是对于一组不知道分类标签的数据,可以通过聚类算法自动的把相似的数据划分到同一个分类中。即聚类与分类的区别主要在于,聚类可以不必知道源数据的标签信息。
1.2 算法描述
在K-means算法执行过程中,可以通过随机的方式选择初始质心,也只有初始时通过随机方式产生的质心才是实际需要聚簇集合的中心点,而后面通过不断迭代产生的新的质心很可能并不是在聚簇中的点。如果某些异常点距离质心相对较大时,很可能导致重新计算得到的质心偏离了聚簇的真实中心。这在我们上图也可以看到这种情况。
借用百度百科的算法步骤:
(1)随机选择k个代表对象作为初始的中心点
(2)指派每个剩余对象给离它最近的中心点所代表的簇
(3)随机地选择一个非中心点对象y
(4)计算用y代替中心点x的总代价s
(5)如果s为负,则用可用y代替x,形成新的中心点
(6) 重复(2)(3)(4)(5),直到k个中心点不再发生变化.
在网上看到一个例子,感觉过程还是挺清晰的。
2.代码运算实例
我在报告一开始已经将两种算法对比了一下效果,这里就再试一下,不存在孤立点时候的k中心点算法的表现:
依然是一个类,只要传入初始点的个数要定义的中心点个数,便可以画出一开始杂乱无序的图和经过k中心点算法训练后的图。首先看一下一开始的图,我定义了一千个点:

可以看出的确是十分杂乱,接下来看看运行算法后的效果:

不存在孤立点的情况,分出的效果与k-means算法还是大致差不多,如下为k-means运行的效果:

都是差不多的三等分。
3.算法学习心得
这次的实验还是比较简单的,在k-means算法的基础上,修改核心的中心点的划分部分即可。
还是那句话,python作为一个工具,实在是太方便了。
附录:k中心点算法python代码
# -*- coding: utf-8 -*-
# @Time : 18-12-6
# @Author : lin
from sklearn.datasets import make_blobs
from matplotlib import pyplot
import numpy as np
import random
class KMediod():
"""
实现简单的k-medoid算法
"""
def __init__(self, n_points, k_num_center):
self.n_points = n_points
self.k_num_center = k_num_center
self.data = None
def get_test_data(self):
"""
产生测试数据, n_samples表示多少个点, n_features表示几维, centers
得到的data是n个点各自坐标
target是每个坐标的分类比如说我规定好四个分类,target长度为n范围为0-3,主要是画图颜色区别
:return: none
"""
self.data, target = make_blobs(n_samples=self.n_points, n_features=2, centers=self.n_points)
np.put(self.data, [self.n_points, 0], 500, mode='clip')
np.put(self.data, [self.n_points, 1], 500, mode='clip')
pyplot.scatter(self.data[:, 0], self.data[:, 1], c=target)
# 画图
pyplot.show()
def ou_distance(self, x, y):
# 定义欧式距离的计算
return np.sqrt(sum(np.square(x - y)))
def run_k_center(self, func_of_dis):
"""
选定好距离公式开始进行训练
:param func_of_dis:
:return:
"""
print('初始化', self.k_num_center, '个中心点')
indexs = list(range(len(self.data)))
random.shuffle(indexs) # 随机选择质心
init_centroids_index = indexs[:self.k_num_center]
centroids = self.data[init_centroids_index, :] # 初始中心点
# 确定种类编号
levels = list(range(self.k_num_center))
print('开始迭代')
sample_target = []
if_stop = False
while(not if_stop):
if_stop = True
classify_points = [[centroid] for centroid in centroids]
sample_target = []
# 遍历数据
for sample in self.data:
# 计算距离,由距离该数据最近的核心,确定该点所属类别
distances = [func_of_dis(sample, centroid) for centroid in centroids]
cur_level = np.argmin(distances)
sample_target.append(cur_level)
# 统计,方便迭代完成后重新计算中间点
classify_points[cur_level].append(sample)
# 重新划分质心
for i in range(self.k_num_center): # 几类中分别寻找一个最优点
distances = [func_of_dis(point_1, centroids[i]) for point_1 in classify_points[i]]
now_distances = sum(distances) # 首先计算出现在中心点和其他所有点的距离总和
for point in classify_points[i]:
distances = [func_of_dis(point_1, point) for point_1 in classify_points[i]]
new_distance = sum(distances)
# 计算出该聚簇中各个点与其他所有点的总和,若是有小于当前中心点的距离总和的,中心点去掉
if new_distance < now_distances:
now_distances = new_distance
centroids[i] = point # 换成该点
if_stop = False
print('结束')
return sample_target
def run(self):
"""
先获得数据,由传入参数得到杂乱的n个点,然后由这n个点,分为m个类
:return:
"""
self.get_test_data()
predict = self.run_k_center(self.ou_distance)
pyplot.scatter(self.data[:, 0], self.data[:, 1], c=predict)
pyplot.show()
test_one = KMediod(n_points=1000, k_num_center=3)
test_one.run()
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
