社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
前言:7月13号 至7月26号面试总结
比较棘手的的问题:
近来面试找工作经常会遇见这种问题: 做过数据库优化吗?大数据量基础过吗?系统反应慢怎么查询?
这时候就需要你谈一下sql优化相关的内容 , 一下几个方面
1、慢查询
2、索引
3、拆分表
数据库索引变快
全部检索(扫描)
系统集成
二叉树算法--》索引文件 物理位置
log2N 检索10次可以检索2的10次方个数(1024)
全文索引,主要是针对对文件,文本的检索, 比如文章, 全文索引针对MyISAM有用.
select * from articles where match(title,body) against(‘database’); 【可以】
唯一索引
unique空串(null)可以放多个 如果是具体的内容则不能重复
a: 肯定在where条经常使用
b: 该字段的内容不是唯一的几个值(sex) (只有三个数据形成2级二叉树)
c: 字段内容不是频繁变化.
联合索引
分表、水平分割
知识点、项目
sql优化(查询9:1)
1. 尽量使用列名(Oracle9i之后, *和列名一样)
在业务密集的SQL当中尽量不采用IN操作符,用EXISTS 方案代替。
2、模糊查询like
关键词%yue%,由于yue前面用到了“%”,因此该查询必然走全表扫描,除非必要,否则不要在关键词前加%,
3 二者都能使用尽量使用where (与having比较)
where 先过滤(数据就少了)在分组
4: 理论上,尽量使用多表连接(join)查询(避免子查询)
show status like 'uptime';
show [session|global] status like 'com_select';
show status like 'connections';
慢查询(默认10秒)
show status like 'slow_querties';
以安全模式启动
SHOW INDEX FROM emp
BTREE
20180327更新
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
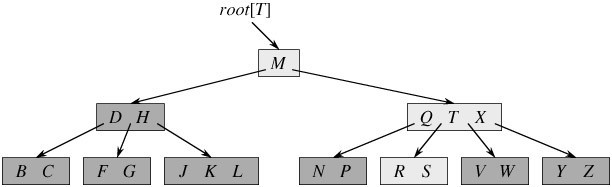
从上图你能看到,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女
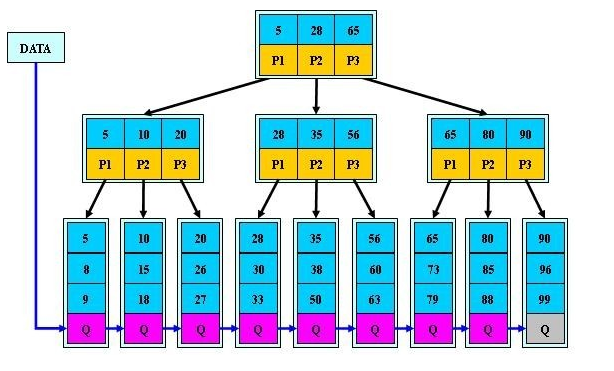
为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对于B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶结点data域保存了完整的数据记录。
MyISAM的索引方式也叫做“非聚集”的
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
