社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
1 Go的应用场景
在斗鱼我们将GO的应用场景分为以下三类,缓存类型数据,实时类型数据,CPU密集型任务。这三类应用场景都有着各自的特点。
● 缓存类型数据在斗鱼的案例就是我们的首页,列表页,这些页面和接口的特点是不同用户在同一段时间得到的数据都是一样的,通常这些缓存类型数据的包都比较大,并且这些数据没有用户态,具有一定价值,很容易被爬虫爬取。针对这三种业务场景如何做优化,我们也是走了不少弯路。而且跟一些程序员一样,容易陷入到特定的技术和思维当中去。举个简单的例子。早期我们在优化GO的排序引擎的时候,上来就想着各种算法优化,引入了跳跃表,归并排序,看似优化了不少性能,benchmark数据也比较好看。但实际上排序的算法时间和排序数据源获取的时间数量级差别很大。优化如果找不对方向,业务中的优化只能是事倍功半。所以在往后的工作中,我们基本上是按照如下图所示的时间区域,找到业务优化的主要耗时区域。
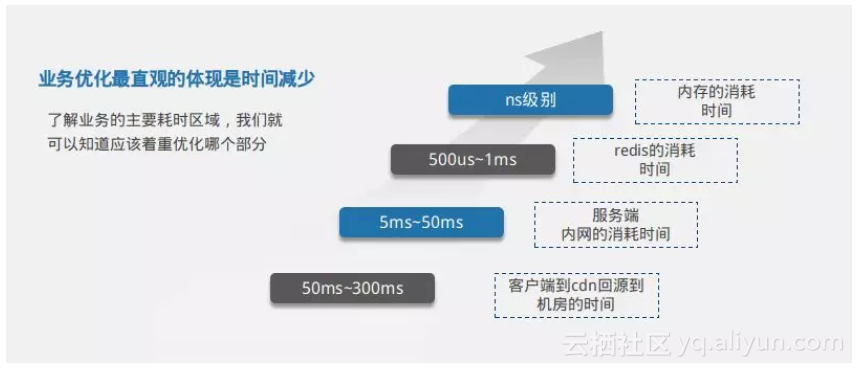
从图中,我们主要列举了几个时间分布,让大家对这几个数值有所了解。从客户端到CDN回源到机房的时间大概是50ms到300ms。机房内部服务端之间通信大概是5ms到50ms。我们访问的内存数据库redis返回数据大概是500us到1ms。GO内部获取内存数据耗时ns级别。了解业务的主要耗时区域,我们就可以知道应该着重优化哪个部分。
2 Go的业务优化
2.1 缓存数据优化
对于用户访问一个url,我们假定这个url为/hello。这个url每个用户返回的数据结构都是一样的。我们通常有可能会向下面示例这样做。对于开发而言,代码是最直观最可控的。但这种方式通常只是实现功能,但并不能够提升用户体验。因为对于缓存数据我们没有必要每次让CDN回源到源站机房,增加用户访问的链路时间。
e := echo.New()
e.Use(mw.Cache) // Routers
e.GET("/hello", handler(HomeHandler))
2.1.1 添加CDN缓存
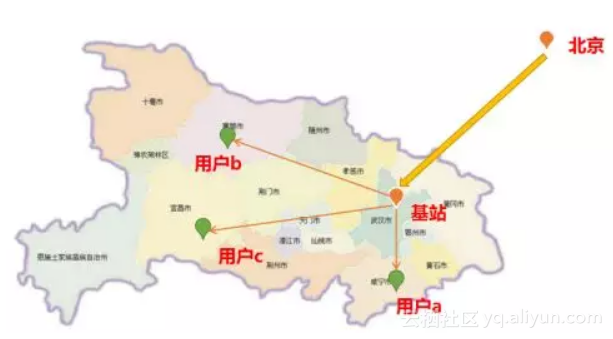
所以接下来,对于缓存数据,我们不会用go进行缓存,而是在前端cdn进行缓存优化。CDN链路如下所示
}
}
go 代码如下所示
import ( "fmt" "io" "net/http")
func main() {
http.Handle("/hello", &ServeMux{})
err := http.ListenAndServe(":9090", nil) if err != nil {
fmt.Println("err", err.Error())
}
}
type ServeMux struct {
}
func (p *ServeMux) ServeHTTP(w http.ResponseWriter, r *http.Request) {
fmt.Println("get one request")
fmt.Println(r.RequestURI)
io.WriteString(w, "hello world")
}
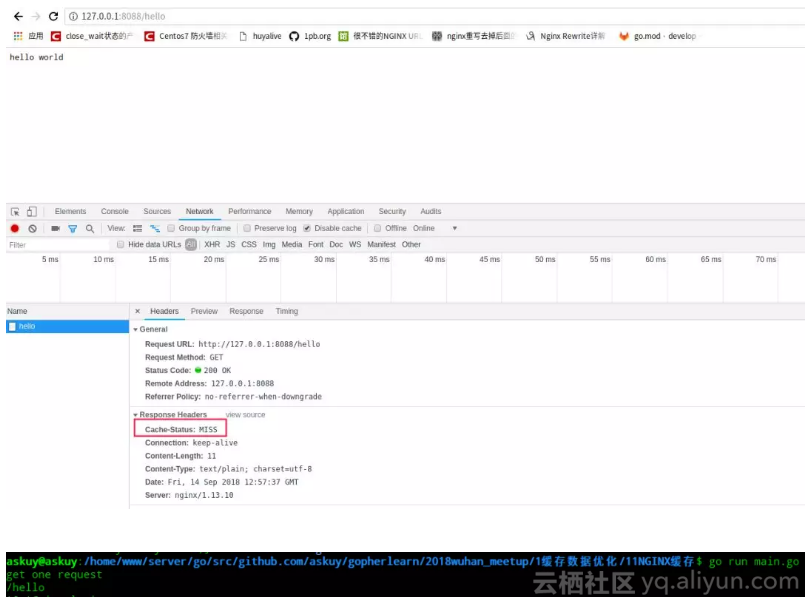
启动代码后,我们可以发现。
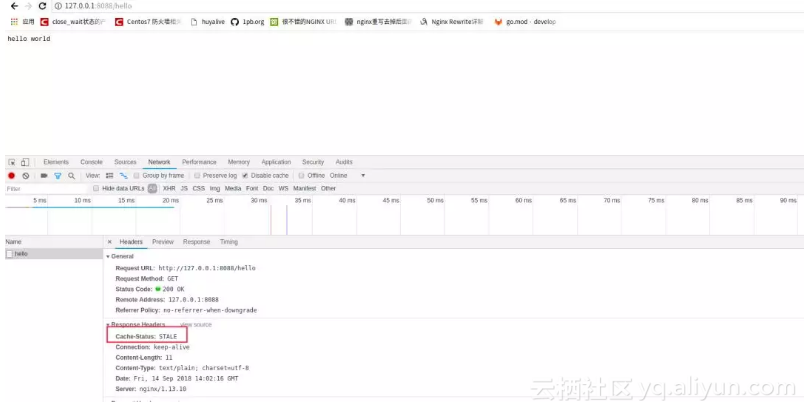
● 第一次访问hello,nginx和go都会收到请求,nginx的响应头里cache-status中会有个miss内容,说明了nginx请求穿透到go
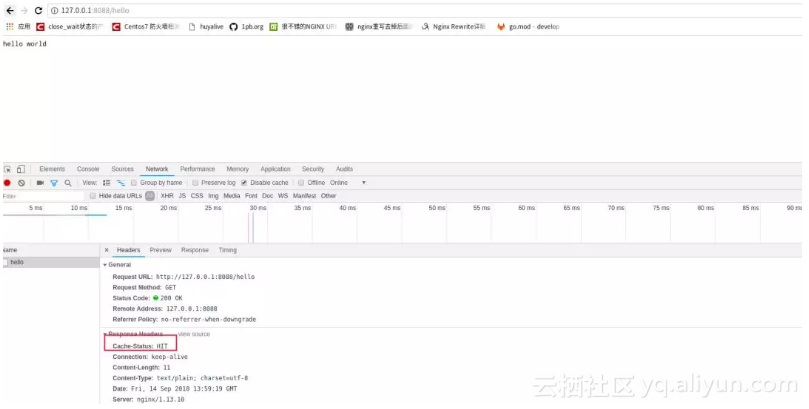
● 第二次再访问hello,nginx会收到请求,go这个时候就不会收到请求。nginx里响应头里cache-status会与个hit内容,说明了nginx请求没有回源到go
● 顺带提下nginx这个配置,还有额外的好处,如果后端go服务挂掉,这个缓存urlhello任然是可以返回数据的。nginx返回如下所
2.1.2 CDN去问号缓存
正常用户在访问hellourl的时候,是通过界面引导,然后获取hello数据。但是对于爬虫用户而言,他们为了获取更加及时的爬虫数据,会在url后面加各种随机数hello?123456,这种行为会导致cdn缓存失效,让很多请求回源到源站机房。造成更大的压力。所以一般这种情况下,我们可以在CDN做去问号缓存。通过nginx可以模拟这种行为。nginx配置如下:
} location ~ /hello { access_log /home/www/logs/hello_access.log; proxy_pass http://127.0.0.1:9090; proxy_cache vipcache; proxy_cache_valid 200 302 20s; proxy_cache_use_stale error timeout invalid_header updating http_500 http_502 http_503 http_504 http_403 http_404; add_header Cache-Status "$upstream_cache_status";
}
}
2.1.3 大流量上锁
之前我们有讲过如果突然之间有大型赛事开播,会出现大量用户来访问。这个时候可能会出现一个场景,缓存数据还没有建立,大量用户请求仍然可能回源到源站机房。导致服务负载过高。这个时候我们可以加入proxy_cache_lock和proxy_cache_lock_timeout参数
} location ~ /hello { access_log /home/www/logs/hello_access.log; proxy_pass http://127.0.0.1:9090; proxy_cache vipcache; proxy_cache_valid 200 302 20s; proxy_cache_use_stale error timeout invalid_header updating http_500 http_502 http_503 http_504 http_403 http_404; proxy_cache_lock on; procy_cache_lock_timeout 1; add_header Cache-Status "$upstream_cache_status";
}
}
2.1.4 数据优化
在上面我们还提到斗鱼缓存类型的首页,列表页。这些页面接口数据通常会返回大量数据。在这里我们拿Go模拟了一次请求中获取120个数据的情况。将slice分为三种情况,未预设slice的长度,预设了slice长度,预设了slice长度并且使用了sync.map。代码如下所示。这里面每个goroutine相当于一次http请求。我们拿benchmark跑一次数据
roomId int
roomName string}func BenchmarkDefaultSlice(b *testing.B) {
b.ReportAllocs() var wg sync.WaitGroup for i := 0; i < b.N; i++ {
wg.Add(1) go func(wg *sync.WaitGroup) { for i := 0; i < 120; i++ {
output := make([]Something, 0)
output = append(output, Something{
roomId: i,
wg.Done()
roomName: strconv.Itoa(i),
})
}
}func BenchmarkPreAllocSlice(b *testing.B) {
}(&wg)
}
wg.Wait()
b.ReportAllocs() var wg sync.WaitGroup for i := 0; i < b.N; i++ {
wg.Add(1) go func(wg *sync.WaitGroup) { for i := 0; i < 120; i++ {
output := make([]Something, 0, 120)
output = append(output, Something{
roomId: i,
wg.Done()
roomName: strconv.Itoa(i),
})
}
}func BenchmarkSyncPoolSlice(b *testing.B) {
}(&wg)
}
wg.Wait()
b.ReportAllocs() var wg sync.WaitGroup var SomethingPool = sync.Pool{
New: func() interface{} {
b := make([]Something, 120) return &b
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_33730836/article/details/89579579
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
