社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
import numpy as np # 导入库
arr1 = np.array([-9,7,4,3])
arr2 = np.array([-9,7,4,3],dtype =float)# 尝试改变为int或者str
print(arr2)
arr3 = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
arr3
# 使用其他函数创建数组
np.arange(0,10,1)
np.linspace(1,10,10)
np.zeros([4,5])
np.ones([2,3])
arr3 + 1 #矩阵运算
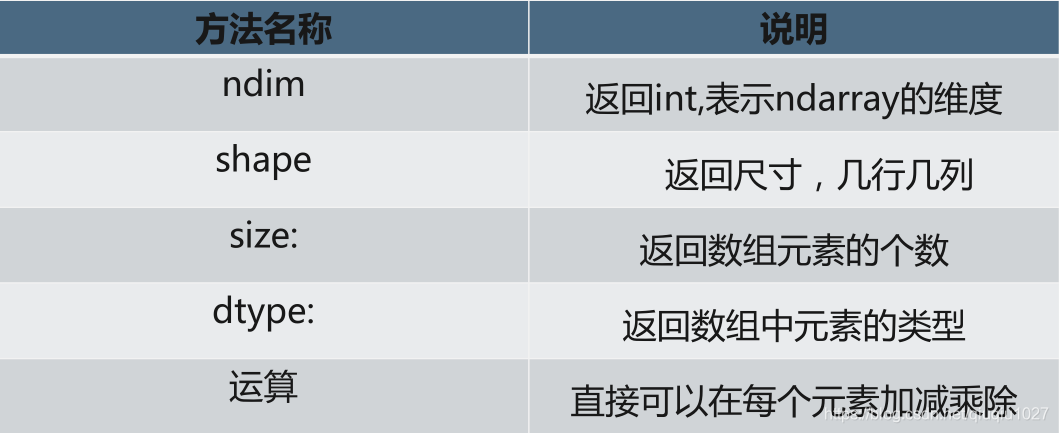
# 查看数组维度
arr3.ndim
arr3.shape
arr3.size
arr3.dtype
arr3 + 1 #矩阵运算
arr3 /2
data2 = ((8.5,6,4.1,2,0.7),(1.5,3,5.4,7.3,9),(3.2,4.5,6,3,9),(11.2,13.4,15.6,17.8,19))
arr2 = np.array(data2)
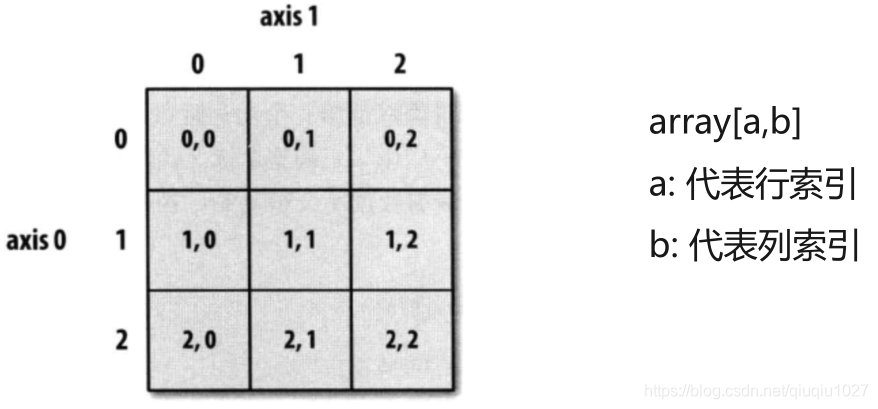
arr2[2] #访问第三行,可以理解为行索引
arr2[2,1] #访问第三行,可以理解为行索引
arr2[:,2:4] #访问第三列
arr2[1:3] #2行和3行
arr2[1:,2:] #第2行到最后一行,第3列到最后一列
arr2[2,1] #访问第三行,第二个元素,第一个是行索引,第二个是列索引
arr2[2][1] #访问第三行,第二个元素,第一个是行索引,第二个是列索引
排序
降序建议用sorted函数
s = np.array([1,2,3,4,3,1,2,2,4,6,7,2,4,8,4,5])
np.sort(s)
sorted(s,reverse =True)#降序
arr1 = np.array([[0,1,3],[4,2,9],[4,5,9],[1,-3,4]])
np.sort(arr1)
np.sort(arr1,axis = 0) # 0代表沿着行的方向, 1代表沿着列的方向
np.sort(arr1,axis = 1)
argsort返回的是排完序以后,在原数据中的索引位置
返回的是数据中,从小到大的索引值
s = np.array([1,2,3,4,3,1,2,2,4,6,7,2,4,8,4,5])
np.argsort(s)
np.where和np.extract
np.where(s>3,1,-1) # 满足条件的,赋值为3,不满足的赋值为-1,返回的数据长度和s一样
np.extract 只会输出满足条件的数据
np.extract(s>3,s) # 只输出满足条件的数据
1.Pandas常用数据结构series和方法
• 通过pandas.Series来创建Series数据结构。
• pandas.Series(data,index,dtype,name)。
• 上述参数中,data可以为列表,array或者dict。
• 上述参数中, index表示索引,必须与数据同长度,name代表对象的名称
2.Pandas常用数据结构dataframe和方法
• 通过pandas.DataFrame来创建DataFrame数据结构。
• pandas. DataFrame(data,index,dtype,columns)。
• 上述参数中,data可以为列表,array或者dict。
• 上述参数中, index表示行索引, columns代表列名或者列标签
3.series和dataframe常用方法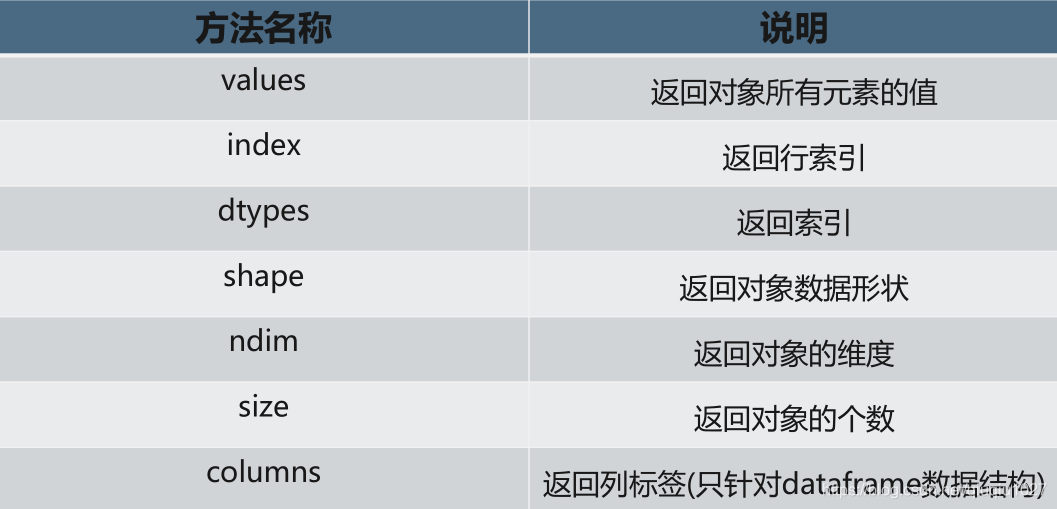
import pandas as pd
import numpy as np
# 构造序列
series1 = pd.Series([2.8,3.01,8.99,8.59,5.18])
series2 = pd.Series([2.8,3.01,8.99,8.59,5.18],index = ['a','b','c','d','e'],name ='这是一个series')
series3 = pd.Series({'北京':2.8,'上海':3.01,'广东':8.99,'江苏':8.59,'浙江':5.18})
#series方法
series2.values
series3.index
# 构造数据框
#数据框其实就是一个二维表结构,是数据分析中,最常用的数据结构
list1 = [['张三',23,'男'],['李四',27,'女'],['王二',26,'女']]#使用嵌套列表
df1 = pd.DataFrame(list1,columns=['姓名','年龄','性别'])
type(df1)
df2 = pd.DataFrame({'姓名':['张三','李四','王二'],'年龄':[23,27,26],'性别':['男','女','女']}) #使用字典,字典的键被当成列名
df2
array1 = np.array([['张三',23,'男'],['李四',27,'女'],['王二', 26,'女']]) #使用numpy
df3 = pd.DataFrame(array1,columns=['姓名','年龄','性别'],index = ['a','b','c'] )
#dataframe方法
df2.values
df2.index
df2.columns
df2.dtypes
df2.ndim
df2.size
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
