社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
c字符串是以空字符结尾的字符串,redis中使用sds(Simple Dynamic String, 简单动态字符串)代替c字符串,sds定义: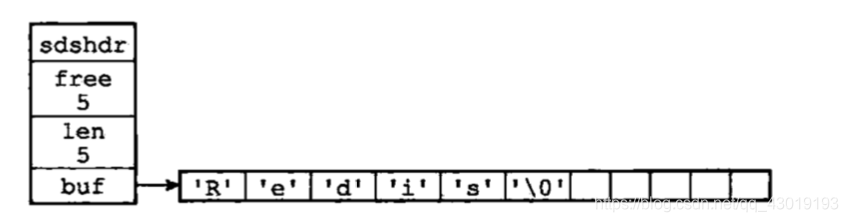
区别如下: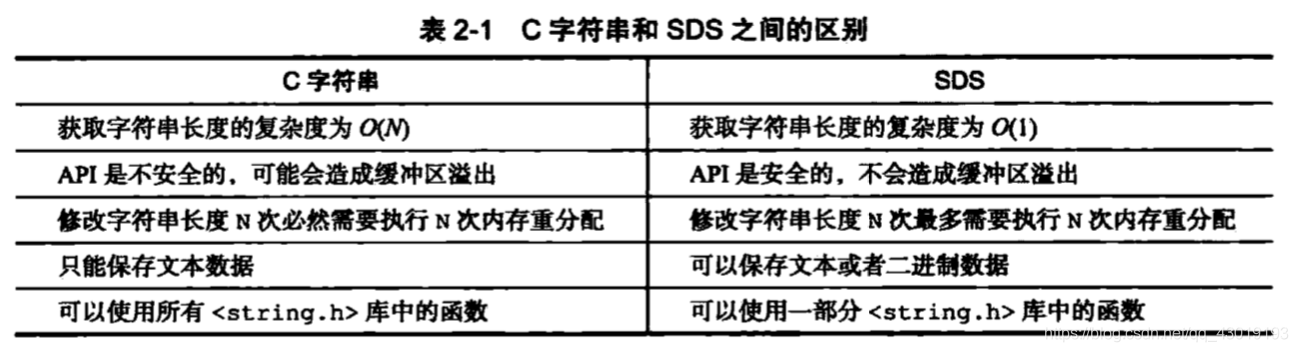
会有一些 bool 型数据需要存取,比如用户一年的签到记录, 签了是 1,没签是 0,要记录 365 天。如果使用普通的 key/value,每个用户要记录 365 个,当用户上亿的时候,需要的存储空间是惊人的。
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。
Redis数据库使用字典来作为底层实现的。对数据库的增删改查也是构建在对字典的操作之上
字典的底层是使用哈希表来实现的。
保存k0, v0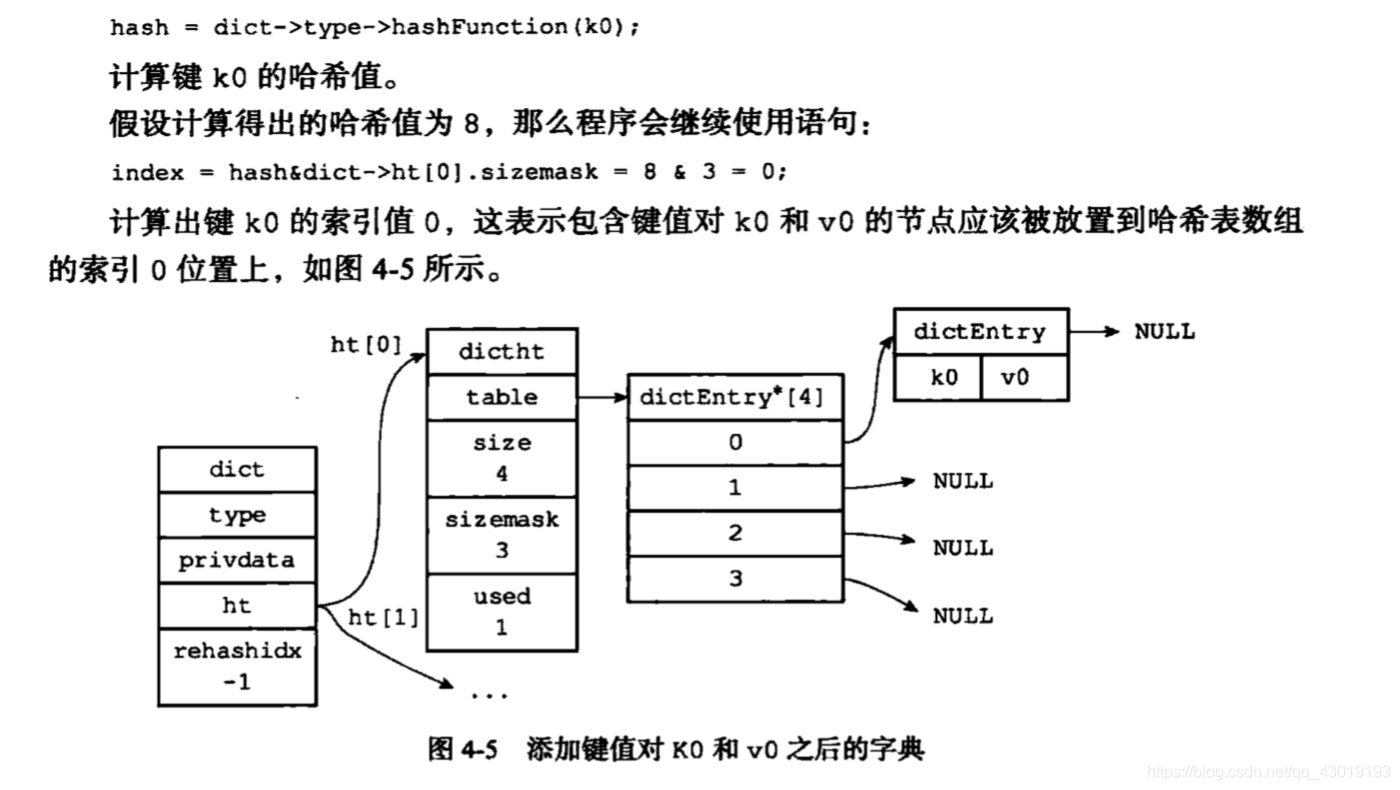
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是 压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的 时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且 会加重内存的碎片化。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next 。所以 Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空 间冗余。
2.8以前不是原子的。(有可能造成死锁)
提供不精确的计数方案,标准误差是0.81%
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某 个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合 理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存 在。打个比方,当它说不认识你时,肯定就不认识;当它说见过你时,可能根本就没见过 面,不过因为你的脸跟它认识的人中某脸比较相似 (某些熟脸的系数组合),所以误判以前见 过你。
Redis 的事务根本不能算「原子性」,而仅仅是满足了事务的「隔 离性」,隔离性中的串行化——当前执行的事务有着不被其它事务打断的权利。
上面的 Redis 事务在发送每个指令到事务缓存队列时都要经过一次网络读写,当一个事 务内部的指令较多时,需要的网络 IO 时间也会线性增长。所以通常 Redis 的客户端在执行 事务时都会结合 pipeline 一起使用,这样可以将多次 IO 操作压缩为单次 IO 操作
1.定是删除
2.惰性删除
https://baijiahao.baidu.com/s?id=1594341157941741587&wfr=spider&for=pc
redis是单线程的,在保存快照的时候,会调用操作系统的cow(copy on write), fork 出一个子进程,主进程继续处理请求,子进程进行copy。当主进程有修改时,会复制一个大小为4k的分页,这个操作对子进程来说是透明的。所以子进程复制的还是修改的之前的内容。这样就会导致有数据丢失
aof保存的是指令流,当redis接受一个指令时,会先保存指令,在执行。这样根据aof可以把一个空的redis 恢复成原先的样子。但是随着时间的增长,aof会变得越来越大。因为redis是单线程的,所以恢复的时候会特别缓慢,可能无法处理其他的请求。
在redis4.0版本,退出了混合持久性。在rdb开启的时候,进行aof操作,这样的保存快照的时候操作也可以被保存下来,保证数据不会丢失,同时也解决了aof臃肿的问题。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
