社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
**
python-如何爬取天猫店铺的商品信息
**
1.本文使用的是python-scrapy 爬取天猫博库图书专营店的数据,登录天猫 获取登录之后的cookie
通过下面两幅图片elements与网页源码对比不难看出,我们通过代码获取的源码与elements是对不上的,也就是说需要我们自己查找数据所在位置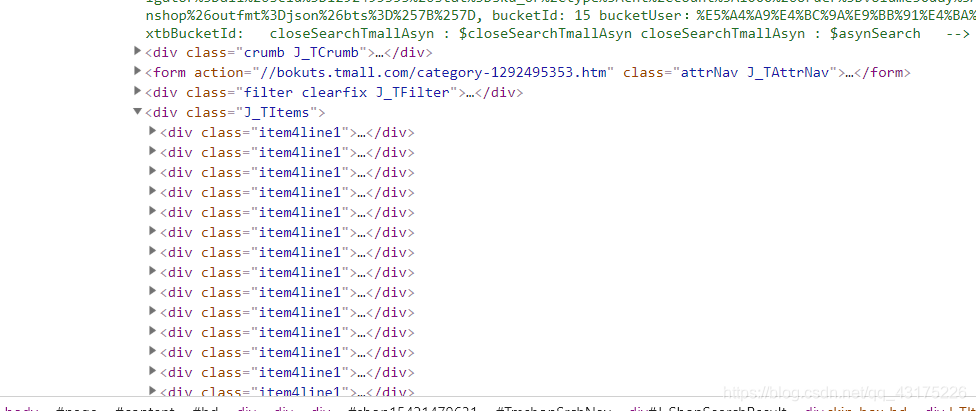

下面重点来了!!!
通过network中的对请求进行抓包,查看,获取了如下网址
请求该网址可以看到获取了如下内容
此时再查看elements与源码发现终于对应上了,松了一口气,但是还有一个问题,这个网址还需要解析呢,不难,看下去就明白了
通过对获取的网址进行删减,我们可以获取到如下url
https://bokuts.tmall.com/i/asynSearch.htm?callback=jsonp119&mid=w-15421479631-0&wid=15421479631&path=/category-1292495385.htm&spm=a1z10.5-b-s.w4011-15421479631.132.2d944a88DdcUWW&search=y&scene=taobao_shop&catId=1292495385&pageNo=2&scid=1292495385
https://bokuts.tmall.com/i/asynSearch.htm?callback=jsonp119&mid=w-15421479631-0&wid=15421479631&path=/category-1292493589.htm&spm=a1z10.5-b-s.w4011-15421479631.133.59b94a88Cyzcqr&search=y&scene=taobao_shop&catId=1292493589&pageNo=4&scid=1292493589
对不可以看到不同点共有四个:category,spm,catId,pageNo,
pageno 是页数,不要管,那还剩三个参数在哪里呢?回头看一开始的请求网址
https://bokuts.tmall.com/category-1292495365.htm?spm=a1z10.5-b-s.w4011-15421479631.158.3cd61e78EvCORk&search=y&catId=1292495365&pageNo=1#anchor
全部都在里面,接下来就好办了,通过正则匹配提取参数,发送请求,xpath提取,直接上代码:
# -*- coding: utf-8 -*-
import json
import re
import time
import scrapy
class BkSpider(scrapy.Spider):
name = 'bk'
allowed_domains = ['bokuts.tmall.com']
# start_urls = ['https://bokuts.tmall.com/category-1292495365.htm?spm=a1z10.5-b-s.w4011-15421479631.158.3cd61e78EvCORk&search=y&catId=1292495365&pageNo=1#anchor']
def start_requests(self):
url = input("请输入要爬取的url")
start_url = url
yield scrapy.Request(
start_url,
callback=self.parse
)
def parse(self, response):
category = re.findall(r"category-(.*?).htm",response.url)[0]
spm = re.findall(r"?spm=(.*?)&search",response.url)[0]
# catname = re.findall(r"catName=(.*?)&scene",response.url)[0]
cat_id = re.findall(r"catId=(.*?)&pageNo",response.url)[0]
pageno = re.findall(r"pageNo=(d+)",response.url)[0]
scid = cat_id
price_url = "https://bokuts.tmall.com/i/asynSearch.htm?callback=jsonp119&mid=w-15421479631-0&wid=15421479631&path=/category-{}.htm&spm={}&search=y&scene=taobao_shop&catId={}&pageNo={}&scid={}".format(category, spm, cat_id, pageno, scid)
yield scrapy.Request(
price_url,
callback=self.get_book_info,
meta={"num": pageno}
)
def get_book_info(self, response):
num = response.meta["num"]
dl_list = response.xpath("//div[@class='\"J_TItems\"']/div[@class='\"item4line1\"']/dl")[:-8]
list_content = []
for dl in dl_list:
item = {}
item["book_title"] = dl.xpath("./dd[@class='\"detail\"']/a/text()").extract_first()
item["book_price"] = dl.xpath(".//div[@class='\"cprice-area\"']/span[@class='\"c-price\"']/text()").extract_first().strip()
item["sale"] = dl.xpath(".//div[@class='\"sale-area\"']/span[@class='\"sale-num\"']/text()").extract_first()
item["eva_count"] = dl.xpath(".//dd[@class='\"rates\"']//h4/a/span/text()").extract_first()
item["detail_href"] = dl.xpath(".//dd[@class='\"detail\"']/a/@href").extract_first()[2:-3]
item["detail_href"] = "https:" + item["detail_href"]
list_content.append(item)
for i in list_content:
with open("第{}页.txt".format(num), "a", encoding="utf-8") as f:
f.write(json.dumps(i,ensure_ascii=False, indent=2))
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url is None:
return
else:
next_url = next_url[2:-1]
next_url = "https:" + next_url
print(next_url)
time.sleep(5)
yield scrapy.Request(
next_url,
callback=self.parse
)
以上就是本人爬取天猫的一点经验,如有错误,欢迎指正!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
