社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
笼统的来说,go的map底层是一个hash表(HashMap),表面上看map只有键值对结构,实际上在存储键值对的过程中涉及到了数组和链表。HashMap之所以高效,是因为其结合了顺序存储(数组)和链式存储(链表)两种存储结构。数组是HashMap的主干,在数组下有一个类型为链表的元素。
哈希函数会将传入的key值进行哈希运算,得到一个唯一的值。go语言把生成的哈希值一分为二,比如一个key经过哈希函数,生成的哈希值为:8423452987653321,go语言会这它拆分为84234529,和87653321。那么,前半部分就叫做高位哈希值,后半部分就叫做低位哈希值。
高位哈希值:是用来确定当前的bucket(桶)有没有所存储的数据的。
低位哈希值:是用来确定,当前的数据存在了哪个bucket(桶)
hmap是map的最外层的一个数据结构,包括了map的各种基础信息、如大小、bucket。首先说一下,buckets这个参数,它存储的是指向buckets数组的一个指针,当bucket(桶为0时)为nil。我们可以理解为,hmap指向了一个空bucket数组,并且当bucket数组需要扩容时,它会开辟一倍的内存空间,并且会渐进式的把原数组拷贝,即用到旧数组的时候就拷贝到新数组。
bucket(桶),每一个bucket最多放8个key和value,最后由一个overflow字段指向下一个bmap,注意key、value、overflow字段都不显示定义,而是通过maptype计算偏移获取的。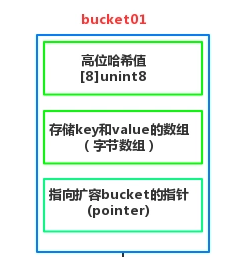
bucket这三部分内容决定了它是怎么工作的:
bucket时,hmap会拓展该bucket。
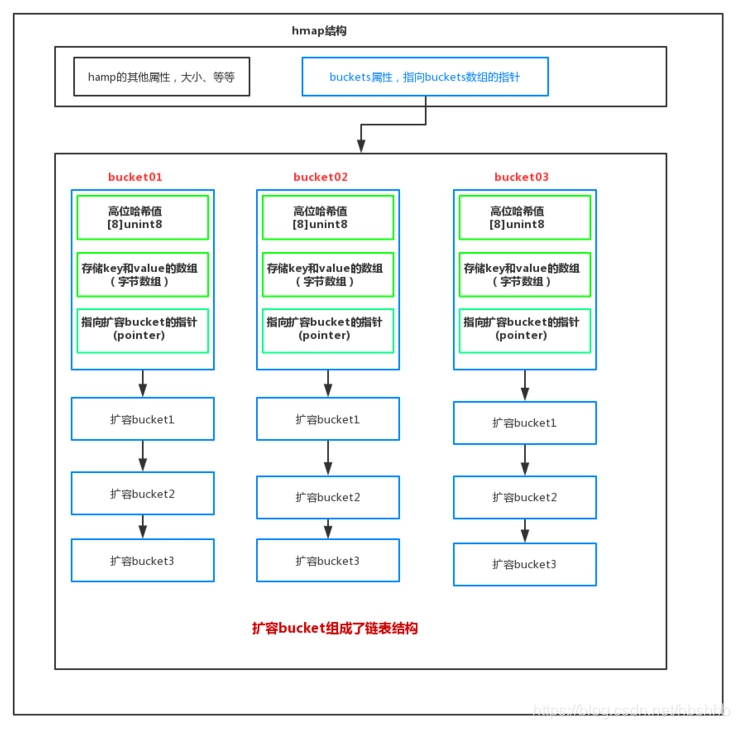
如图所示:
hmap存储了一个指向底层bucket数组的指针。
我们存入的key和value是存储在bucket里面中,如果key和value大于128字节,那么bucket里面存储的是指向我们key和value的指针,如果不是则存储的是值。
每个bucket 存储8个key和value,如果超过就重新创建一个bucket挂在在元bucket上,持续挂接形成链表。
高位哈希值:是用来确定当前的bucket(桶)有没有所存储的数据的。
低位哈希值:是用来确定,当前的数据存在了哪个bucket(桶)
简单结构为图: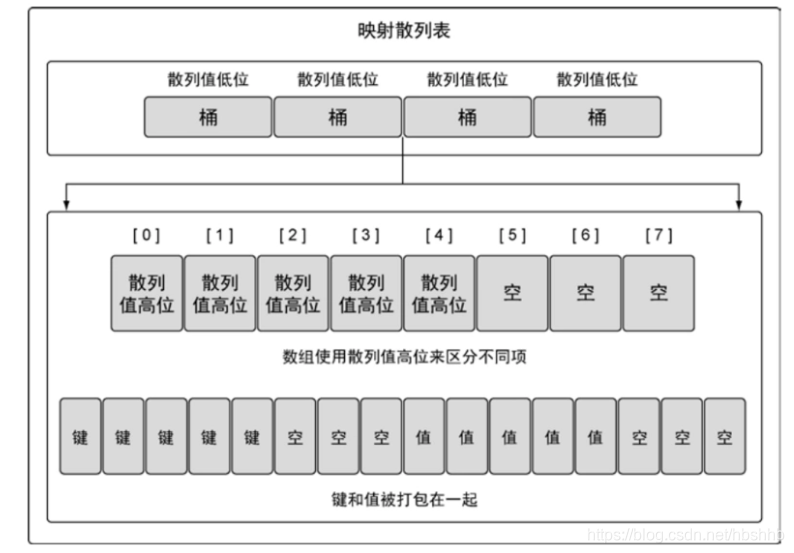
工作流程:
查找或者操作map时,首先key经过hash函数生成hash值,通过哈希值的低8位来判断当前数据属于哪个桶(bucket),找到bucket以后,通过哈希值的高八位与bucket存储的高位哈希值循环比对,如果相同就比较刚才找到的底层数组的key值,如果key相同,取出value。如果高八位hash值在此bucket没有,或者有,但是key不相同,就去链表中下一个溢出bucket中查找,直到查找到链表的末尾。
碰撞冲突:如果不同的key定位到了统一bucket或者生成了同一hash,就产生冲突。 go是通过链表法来解决冲突的。比如一个高八位的hash值和已经存入的hash值相同,并且此bucket存的8个键值对已经满了,或者后面已经挂了好几个bucket了。那么这时候要存这个值就先比对key,key肯定不相同啊,那就从此位置一直沿着链表往后找,找到一个空位置,存入它。所以这种情况,两个相同的hash值高8位是存在不同bucket中的。
查的时候也是比对hash值和key 沿着链表把它查出来。 还有一种情况,就是目前就 1个bucket,并且8个key-value的数组还没有存满,这个时候再比较完key不相同的时候,同样是沿着当前bucket数组中的内存空间往后找,找到第一个空位,插入它。这个就相当于是用寻址法来解决冲突,查找的时候,也是先比较hash值,再比较key,然后沿着当前内存地址往后找。
go语言的map通过数组+链表的方式实现了hash表,同时分散各个桶,使用链表法+bucket内部的寻址法解决了碰撞冲突,也提高了效率。因为即使链表很长了,go会根据装载因子,去扩容整个bucket数组,所以下面就要看下扩容。
6.5(元素个数/bucket),bmap就会进行扩容,将原来bucket数组数量扩充一倍,产生一个新的bucket数组,也就是bmap的buckets属性指向的数组。这样bmap中的oldbuckets属性指向的就是旧bucket数组。如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
