社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
实战项目是获取指定CSDN博主的全部博客并保存在本地,命名方式为“博客名称+.html”。
声明:这一实战项目违反了CSDN的robots协议,仅用于学习交流之用。
在阅读CSDN博客的时候,经常会遇到大神,博客篇篇精华,每篇都想保存下来。有的大神是博客大户,几百篇文章之多,一个个保存手腕要废掉了。在学习了爬虫之后,就想爬虫把大神博客自动保存下来。话不多说,进入实战!
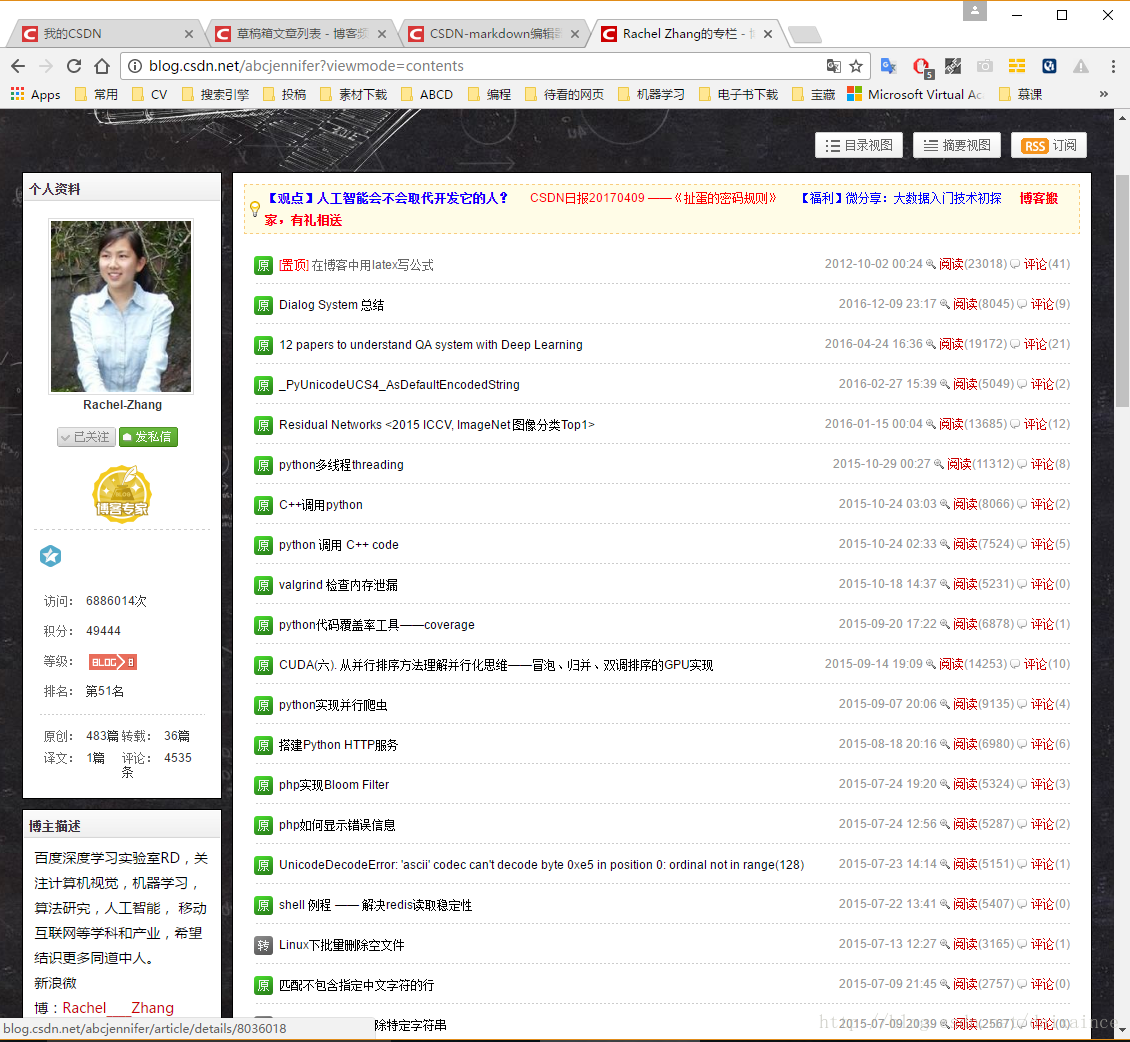
结合大神博客,我们对项目进行分析,这里选的大神是abcjennifer,查看模式使用的是目录模式:
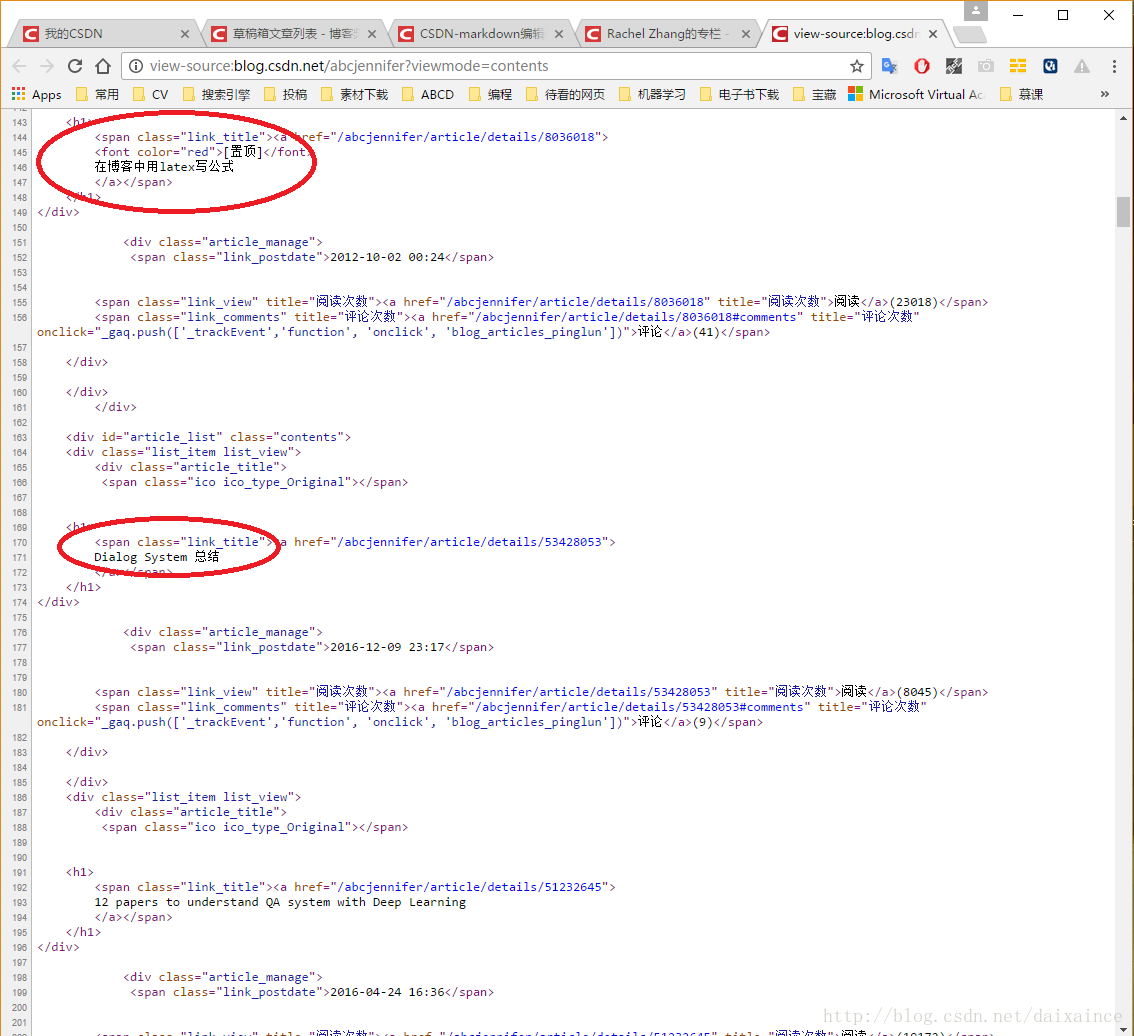
再看以下源码:
乍一看源码好晕,但是和文章名称对应一下,就能发现规律。红框中的部分就是文章的名称,在span标签内,class均为link_title,后面的< a href >标签里是文章的链接,再仔细辨别,每个文章名称都在span标签内。这样就能获取文章名称和对应链接了,存入字典类型中,就可以方便的命名并获取指定链接的内容了。
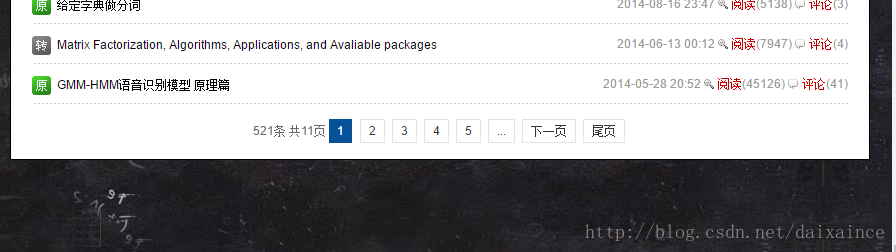
大神的博客不止一页,往下翻,有11页521条:
页面个数可以提取,使用re库直接提取’共d?页’匹配的内容就能提取页面个数了。
下面再看第二页的内容,第二页的网址是http://blog.csdn.net/abcjennifer/article/list/2 ,第三页是http://blog.csdn.net/abcjennifer/article/list/3 ,规律出来了,可以进行自动化作业了。接下来的步骤就是获取不同页面的源代码,提取文章名称和链接,获取文章内容并保存。
分析结束后,按照功能划分除下列函数:
话不多说,show the
code。
def getHTMLText(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(url, headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "" 使用try…except的目的是使代码能够正常运行不报错误,header的定义是突破CSDN的限制。
raise_for_status()函数的作用是在获取内容不正确的情况下,产生错误,使代码跳到except继续运行。
def getLinkFromHTML(html, links):
try:
soup = BeautifulSoup(html, 'html.parser')
for i in soup.find_all(attrs = {'class':'link_title'}):
name = i.a.contents[-1]
if name==None:
continue
else:
#print name.strip()
link = i.a.attrs['href']
links[name.strip()] = link
except:
return利用bs库和link_title关键字,提取出文章名称和链接。使用a.contents[-1]的目的是消除”[置顶]“二字对提取的干扰,直接使用a.string适用于大多数情况,遇见< font >< /font >标签后,不能正确提取文章标题。links为字典类型变量。
def getPageNumFromHTML(html):
try:
return int(re.search(u"u5171d+u9875",html).group(0)[1:-1])
except:
return -1u”u5171d+u9875”就是“共d+页”的意思,因为只需要页码数,因此保留匹配字符串中的第二个至倒数第二个部分。只有一页就返回-1。
def saveHTML(fpath, html):
f = open(fpath, 'w')
f.write(html)
f.close()不多介绍,’w’表示以写模式打开。
def getCSDNBlog(ID, path):
# 判断路径是否存在,不存在则新建
if os.path.exists(path)==False:
os.mkdir(path)
# 根据ID构造网址
url = 'http://blog.csdn.net/'+ID+'/article/list/1'
html = getHTMLText(url)
pages = getPageNumFromHTML(html)
links = {}
# 获取首页链接
getLinkFromHTML(html, links)
# 获取剩余页面链接
for i in range(2,pages+1):
url = 'http://blog.csdn.net/'+ID+'/article/list/'+str(i)
html = getHTMLText(url)
getLinkFromHTML(html,links)
# 获取文章内容并保存
for key in links.keys():
html = getHTMLText('http://blog.csdn.net'+links[key])
fpath = path+re.sub(r'[<>|":/?*]',r'_',key)+'.html'
print('saving '+fpath)
saveHTML(fpath, html)注释在,不多说。fpath在保存之前,根据windows的命名规则,用’_’代替其中不合适的部分。
完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 29 22:23:32 2017
爬取指定CSDN博主全部博客(几乎)
@author: Darcy
"""
import requests
import re
from bs4 import BeautifulSoup
import os
import sys
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
def getHTMLText(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(url, headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getLinkFromHTML(html, links):
try:
soup = BeautifulSoup(html, 'html.parser')
for i in soup.find_all(attrs = {'class':'link_title'}):
name = i.a.contents[-1]
if name==None:
continue
else:
#print name.strip()
link = i.a.attrs['href']
links[name.strip()] = link
except:
return
def getPageNumFromHTML(html):
try:
return int(re.search(u"u5171d+u9875",html).group(0)[1:-1])
except:
return -1
def saveHTML(fpath, html):
f = open(fpath, 'w')
f.write(html)
f.close()
def getCSDNBlog(ID, path):
if os.path.exists(path)==False:
os.mkdir(path)
url = 'http://blog.csdn.net/'+ID+'/article/list/1'
html = getHTMLText(url)
pages = getPageNumFromHTML(html)
links = {}
getLinkFromHTML(html, links)
for i in range(2,pages+1):
url = 'http://blog.csdn.net/'+ID+'/article/list/'+str(i)
html = getHTMLText(url)
getLinkFromHTML(html,links)
#print len(links)
for key in links.keys():
html = getHTMLText('http://blog.csdn.net'+links[key])
fpath = path+re.sub(r'[<>|":/?*]',r'_',key)+'.html'
print('saving '+fpath)
saveHTML(fpath, html)
def main():
path = 'D:/test/'
ID = 'abcjennifer'
getCSDNBlog(ID, path)
main()代码就是提取abcjennifer大神的全部博客。
注意:上述代码并没有提取博客中的图片,只是保存了图片的地址,以后再改进吧!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!