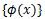社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
上星期写了Kaggle竞赛的详细介绍及入门指导,但对于真正想要玩这个竞赛的伙伴,机器学习中的相关算法是必不可少的,即使是你不想获得名次和奖牌。那么,从本周开始,我将介绍在Kaggle比赛中的最基本的也是运用最广的机器学习算法,很多项目用这些基本的模型就能解决基础问题了。
那么,今天就开始更新集成学习之Gradient Boosting梯度提升。
共 3 种思路:

学习Gradient Boosting之前,我们先来了解一下增强集成学习(Boosting)思想:

AdaBoost详细学习可参考机器学习----集成学习(Boosting)
解释上图过程(Ada Boosting 的思路):第一次进行学习得到第一个子模型,根据第一子模型的预测结果重新定义数据集——将预测错误的点(深色点)划分较高权重,将预测成功的点(浅色点)划分较低权重;第二次进行学习时,使用上一次学习后被重新定义的数据集进行训练,再根据模型的预测结果重新定义数据集——将预测错误的点(深色点)划分较高权重,将预测成功的点(浅色点)划分较低权重;以此类推,最终得到 n 个子模型;
主要原理: 通过给已有模型预测错误的样本更高的权重,不断更新样本数据分布,每轮训练中(根据训练后的分类对错,调整样本权重)为每个训练样本重新赋予一个权重。
怎么为样本赋权值,让下一子模型对不同权值的样本区别对待?
scikit-learn 中封装的 Ada Boosting 集成学习算法:
AdaBoostClassifier(): 解决分类问题;
AdaBoostRegressor(): 解决回归问题;
使用格式:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=500)
ada_clf.fit(X_train, y_train)
注:AdaBoostingClassifier() 的参数的使用可查文档;
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法。GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。
GBDT主要由三个概念组成:Regression Decision Tree(即DT)、Gradient Boosting(即GB)、Shrinkage(算法的一个重要演进分支,目前大部分源码都按该版本实现)。理解这三个概念后就能明白GBDT是如何工作。
提到决策树(DT, Decision Tree),绝大部分人首先想到的就是C4.5分类决策树。但如果一开始就把GBDT中的树想成分类树,那就是一条歪路走到黑,千万不要以为GBDT是很多棵分类树。决策树分为两大类,回归树和分类树。前者用于预测实数值,如明天的温度、用户的年龄、网页的相关程度;后者用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面。这里要强调的是,前者的结果加减是有意义的,如10岁+5岁-3岁=12岁;后者则无意义,如男+男+女=男还是女?GBDT的核心在于累加 所有树的结果作为最终结果,而分类树的结果显然是无法累加的。所以GBDT中的树都是回归树,不是分类树,这点对理解GBDT相当重要,尽管GBDT调整后也可用于分类,但不代表GBDT的树是分类树。
下面以对人的性别判别/年龄预测为例来说明,每个实例都是一个已知性别/年龄的人,而特征则包括这个人上网的时长、上网的时段、网购所花的金额等。
作为对比,先说分类树。我们知道C4.5分类树在每次分支时,是穷举每一个feature的每一个阈值,找到使得按照feature<=阈值和feature>阈值分成的两个分支的熵最大的feature和阈值,按照该标准分支得到两个新节点,用同样方法继续分支直到所有人都被分入性别唯一的叶子节点,或达到预设的终止条件,若最终叶子节点中的性别不唯一,则以多数人的性别作为该叶子节点的性别。
回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)都会得到一个预测值。以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分支时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差,即每个人的年龄与预测年龄的误差平方和除以N。这很好理解,被预测出错的人数越多,均方差越大,通过最小化均方差能够找到最靠谱的分支依据。分支直到每个叶子节点上人的年龄都唯一或者达到预设的终止条件(如叶子个数上限)。若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄作为该叶子节点的预测年龄。
提升树是迭代多棵树来共同决策,怎么实现呢?难道每棵树独立训练一遍,取平均值吗?当然不是,这是投票方法,并不是GBDT,此外只要训练集不变,独立训练三次的三棵树必定完全相同,这样没有意义。GBDT是把所有树的结论累加起来得出最终结论的,其核心在于,每一棵树学的是之前所有树结论之和的残差。比如A的真实年龄是18岁,第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶节点,那么累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学习。这就是Gradient Boosting的意义。
AdaBoost算法是模型为加法模型、损失函数为指数函数、学习算法为前向分步算法的二类分类学习方法,是boosting提升方法的一个特例。
Boosting可以表示为
其中w是权重,ϕ是弱分类器的集合。前向分步算法其实是一个贪心算法,在每一步求解弱分类器和参数时不去修改之前已经求好的分类器ϕm和参数Wm。
输入: 训练数据集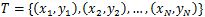

输出: 加法模型f(x)
(1) 初始化
(2) 对m=1, 2, …, M
a) 极小化损失函数得到参数,
b) 更新
(3) 得到加法模型
以上是提升方法的基本结构,可以看到其中存在变数的部分就是极小化损失函数这关键的一步。
不同的损失函数和极小化损失函数方法决定了boosting算法的最终效果,下面是几个常见的boosting:
此外还有Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
Huber损失是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下:
对应的负梯度误差为:
分位数损失对应的是分位数回归的损失函数,表达式为:
其中θ为分位数,需要在回归前指定。对应的负梯度误差为:
对于一般的损失函数,往往每一步优化没那么容易,如上面的绝对值损失函数。针对这一问题,Freidman提出了梯度提升算法,利用最速下降的近似方法,即利用损失函数的负梯度在当前模型中的值作为回归问题中提升树算法的残差近似值,拟合一个回归树。
第t轮第i个样本的损失函数负梯度表示为:
利用可以拟合一棵CART回归树,得到第t棵回归树,其对应的叶节点区域,其中J为叶节点的个数。
针对每一个叶节点里的样本,求出使损失函数最小,也就是拟合叶节点最好的输出值c_tj如下:
这样就得到了本轮的决策树拟合函数,如下:
从而本轮最终得到的强学习器表达式如下:
梯度下降作为求解确定可微方程的常用方法而被人所熟知。它是一种迭代求解方法,具体就是使解沿着当前解所对应梯度的反方向迭代。这个方向也叫做最速下降方向。具体推导过程如下,假定当前已经迭代到第k轮结束,那么第k+1轮的结果怎么得到呢?对函数f做如下一阶泰勒展开:
为了使第k+1轮的函数值比第k轮小,即如下不等式成立:
则只需使
这样一直迭代下去,直到,函数收敛,迭代停止。由于在做泰勒展开时,要求足够小,因此需要γ比较小才行,一般设置为0~1的小数。γ也叫做学习率。
Shrinkage(缩减)的思想认为,每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它不完全信任每一棵残差树,认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学习几棵树来弥补不足。
不使用Shrinkage时,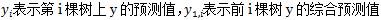
Shrinkage不改变第一个方程,只把第二个方程改为
Shrinkage仍然以残差作为学习目标,但对于残差学习出来的结果,只累加一小部分逐步逼近目标,step一般都比较小,如0.01~0.001(注意这不是gradient的step),导致各棵树的残差是渐变的而不是陡变的。直觉上也很好理解,不像直接用残差一步修复误差,而是只修复一点点,其实就是把大步切成了很多小步。本质上,shrinkage为每棵树设置了一个weight,累加时要乘以这个weight,但和gradient并没有关系。这个weight就是step。像AdaBoost一样,经验证明shrinkage能减少过拟合发生,但目前没有看到理论的证明。
输入:训练样本集,最大迭代次数T,损失函数L
输出:强学习器f(x)
(1) 初始化弱学习器
(2) 对迭代轮数t=1,2,…,T,有
a) 对样本i=1,2,…,N,计算负梯度
b) 利用可以拟合一棵CART回归树,得到第t棵回归树,其对应的叶节点区域,其中J为叶节点的个数。
c) 针叶子区域j=1,2,…,J,计算最佳拟合值:
d) 更新强学习器
(3) 得到强学习器f(x)的表达式
下面是GBDT的大概框架:(Gradient Tree Boosting应该是GBDT另一种说法,有误请指正)
(算法自The Elements of Statistical Learning )
总之,所谓Gradient就是去拟合Loss function的梯度,将其作为新的弱回归树加入到总的算法中即可。
GBDT的分类算法从思想上和GBDT的回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致无法直接从输出类别去拟合类别输出的误差。
为了解决这个问题,主要有两个方法,一个是用指数损失函数,此时GBDT退化为Adaboost算法。另一种方法是用类似于逻辑回归的对数似然损失函数的方法。也就是说,采用类别的预测概率值和真实概率值的差来拟合损失。本文仅讨论用对数似然损失函数的GBDT分类。而对于对数似然损失函数,又有二元分类和多元分类的区别。
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,则损失函数为:
其中。则此时的负梯度误差为
对于生成的决策树,各个叶子节点的最佳残差拟合值为
由于上式比较难优化,一般使用近似值代替
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,二元GBDT分类和GBDT回归算法过程相同。
多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假设类别数为K,则此时对数似然损失函数为:
集合上两式,可以计算出第t轮的第i个样本对应类别l的负梯度误差为
观察上式可以看出,其实这里的误差就是样本i对应类别l的真实概率和t−1轮预测概率的差值。
对于生成的决策树,各个叶子节点的最佳残差拟合值为
由于上式比较难优化,一般使用近似值代替
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,多元GBDT分类和二元GBDT分类以及GBDT回归算法过程相同。
GDBT本身并不复杂,不过要吃透的话需要对集成学习的原理、策树原理和各种损失函树有一定的了解。由于GBDT的卓越性能,只要是研究机器学习都应该掌握这个算法,包括背后的原理和应用调参方法。目前GBDT的算法比较好的库是xgboost。当然scikit-learn也可以。
最后总结下GBDT的优缺点。
GBDT主要的优点有:
缺点:
参考文献:
————————————————
[1] 机器学习之集成学习(四)GBDT 原文链接:https://blog.csdn.net/ivy_reny/article/details/79290745
[2] 集成学习,adaboosting与Gradient Boosting 原理解析 原文链接:https://blog.csdn.net/zhuimeng999/article/details/80387078
[3] 机器学习:集成学习(Ada Boosting 和 Gradient Boosting) 原文链接:https://www.cnblogs.com/volcao/p/9490651.html
[4] 机器学习集成学习算法——boosting系列 原文链接:https://blog.csdn.net/myy1012010626/article/details/80793074
[4] 机器学习相关知识整理系列之三:Boosting算法原理,GBDT&XGBoost 原文链接:https://www.cnblogs.com/csyuan/p/6537255.html
下一篇:逻辑回归(Logistic Regression)原理详解及Python实现
欢迎各位订阅我,谢谢大家的点赞和专注!我会继续给大家分享我大学期间详细的实践项目。 
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!