社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Consumer Group 是Kafka提供的可扩展且具有容错性的消费者机制。在组内多个消费者实例(Consumer Instance ),它们共享一个公共的ID即 Group ID 。组内的所有消费者协调在一起消费订阅主题(Subscribed Topics)的所有分区(Partition)。当然一个分区只能有同一个消费者组的一个Consumer 实例消费。
Consumer Group 有三个特性:
传统的消息系统中,有两种消息引擎模型:点对点模型(消息队列)、发布/订阅模型
传统的两种消息系统各有优势,我们里对比一下:
Kafka 为规避传统消息两种模型的缺点,引入了 Consumer Group 机制:
最理想的情况是Consumer实例的数量应该等于该Group订阅主题的分区总数。例如:Consumer Group 订阅了 3个主题,分别是A、B、C,它们的分区数依次是1、2、3,那么通常情况下,为该Group 设置6个Consumer实例是比较理想的情形。
如果设置小于或大于6的实例可以吗?当然可以,如果你有3个实例,那么平均下来每个实例大约消费2个分区(6/3=2);如果你设置了9个实例,那么很遗憾,有3个实例(9-6=3)将不会被分配任何分区,它们永远处于空闲状态。
消费者在消费的过程中要记录自己消费了多少数据,即消费位置信息,在Kafka中叫:位移(offset)。
看上去该Offset就是一个数字而已,其实对于Consumer Group 而言,它是一组KV对,Key是分区,V对应Consumer 消费该分区的最新位移。
老版本的Consumer Group把位移保存在Zookeeper中。将位移保存在Zookeeper外部系统显然好处是减少了Kafka Broker 端的状态保存开销。现在比较流行的提法是将服务器节点做成无状态的, 这样可以自由扩缩容,实现超强的伸缩性。不过在实际使用场景中,发现ZooKeeper 这类元框架并不是适合进行频繁的写更新,而Consumer Group 的位移更新却是一个非常频繁的操作。 这种大吞吐量的写操作极大的拖慢了ZooKeeper 集群的性能,在新版本的Consumer Group 中,Kafka 社区采用了将Consumer Group 位移保存在Broker 端的内部主题中。
Rebalance 本质上是一种协议,规定了一个Consumer Group 下所有Consumer 如何达成一致,来分配订阅Topic的每个分区。比如:某个Group 下有20个Consumer 实例, 它订阅了一个具有100个分区的Topic。正常情况下,Kafka 平均会为每个Consumer 分配5个分区。这个分配的过程叫Rebalance。
Consumer Group触发 Rebalance有三种情况:
Consumer Group 发生Rebalance 的过程:某个 Consumer Group 下有两个Consumer ,比如A和B,当第三个成员C加入时,Kafka会触发Rebalance,并根据默认的分配策重新分配A、B、C分配分区,如下图: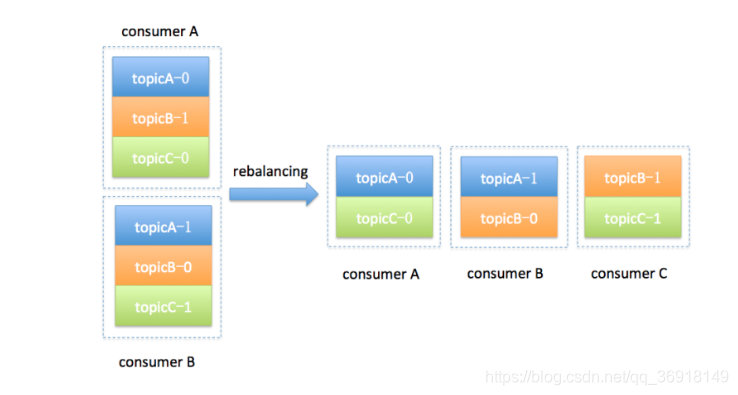
注意:目前Rebalance 的设计是所有Consumer实例共同参与,全部重新分配所有分区,Rebalance过程所有Consumer 实例都会停止消费,等待Rebalance 完成。Rebalance 很慢,一个Group 内有几百个Consumer实例,成功进行一次Rebalance需要好几个小时。 目前社区没有终极解决方案,最好的解决方案是规避Rebalane的发生。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
