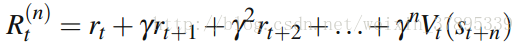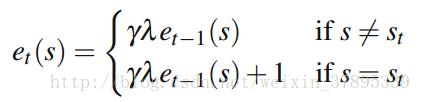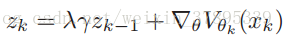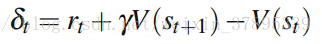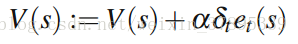社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Monte Carlo算法需要运行完整的episode,利用所有观察到的真是的reward(奖励值)来更新算法。Temporal Difference(TD)算法仅当前时刻采样的reward(奖励值)进行value function的估计。一个折中的方法就是利用n步的reward(奖励进行估计)。
TD(λ)算法:定义0<λ<1,使第k步的奖励乘以系数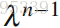
实际中使用的TD(λ)算法称为backward view of the TD(λ) algorithm,该方法通常使用eligibility traces。
eligibility traces是一种将n步的信息备份起来的简洁方式。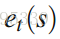
或见过另一种更新方法:
其中λ为衰减因子。该trace在每次访问状态中都会增加,并且上一时刻的trace指数衰减。在时刻t的temporal difference error可以表示如下:
因此,每一步中的value function更新律如下:
对于TD(λ),如果λ=1,则变为Monte Carlo算法,因为考虑了所有时刻的reward返回值。如果λ=0,则变为TD(0)算法,只考虑当前时刻的reward返回值。
eligibility traces算法可以跟所有的model-free(无模型)算法结合使用。
MC使用准确的return reward进行value function的更新,TD使用Bellman equation对value function进行估计,将估计值value的目标值进行更新。TD由于每一步都可以更新,因此学习速度快,用作online learning。由于TD是估计值,因此算法是存在偏差的。但是由于TD对每一步进行估计,只有最近的一步对其有影响,而MC收到整个episode时间段中所有的动作影响,因此TD算法的方差相对MC算法比较小,即波动小。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!