社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
connect-distributed.properties connect-standalone.properties,前者是多节点的配置文件,后者是单节点的配置文件。本文用前者。connect-distributed.propertiesbootstrap.servers=xxxx:9092,xxxx:9092,xxxx:9092
group.id=connect-han
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
offset.flush.interval.ms=10000
rest.port=8083
plugin.path=/app/kafka/connect-plugin
bootstrap.servers 这里是broker的地址;group.id这是connect集群的名字,集群内的多个节点应该一样;rest.port这是connect监听的端口,默认就是8083;plugin.path 这是插件的目录,因为connect自带的插件很少,需要后面我们自己新加插件。
./connect-distributed.sh -daemon /app/kafka/config/connect-distributed.properties
curl -X GET -i 'http://x.x.x.x:8083/connector-plugins'
正常返回
[{"class":"io.confluent.connect.elasticsearch.ElasticsearchSinkConnector","type":"sink","version":"5.0.1"},{"class":"io.confluent.connect.jdbc.JdbcSinkConnector","type":"sink","version":"5.0.1"},{"class":"io.confluent.connect.jdbc.JdbcSourceConnector","type":"source","version":"5.0.1"},{"class":"org.apache.kafka.connect.file.FileStreamSinkConnector","type":"sink","version":"2.1.0"},{"class":"org.apache.kafka.connect.file.FileStreamSourceConnector","type":"source","version":"2.1.0"}]
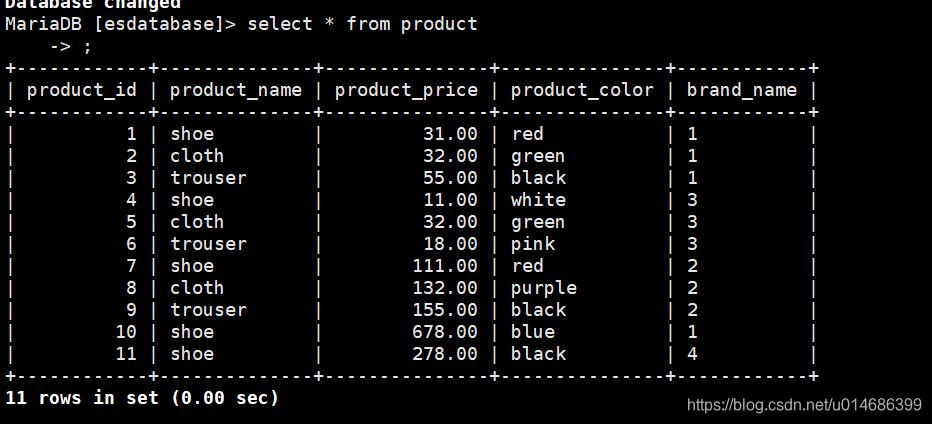
curl -X POST -H 'Content-Type: application/json' -i 'http://x.x.x.x:8083/connectors' --data '{"name":"load-mysql-data",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://x.x.x.x:3306/esdatabase?user=esuser&password=123.com",
"table.whitelist":"product",
"incrementing.column.name": "product_id",
"mode":"incrementing",
"topic.prefix": "test-mysql-jdbc-"
}
}'
name每个连接器的名字是唯一的;connector.class这里用你的JDBC插件的名字;connection.url jdbc的配置;table.whitelist 要导入的表的名字,可以写多个用逗号分隔;incrementing.column.name 自增列的名字,用于增量导入;topic.prefix 创建topic的前缀,这里创建的topic就是 test-mysql-jdbc-proudct 。
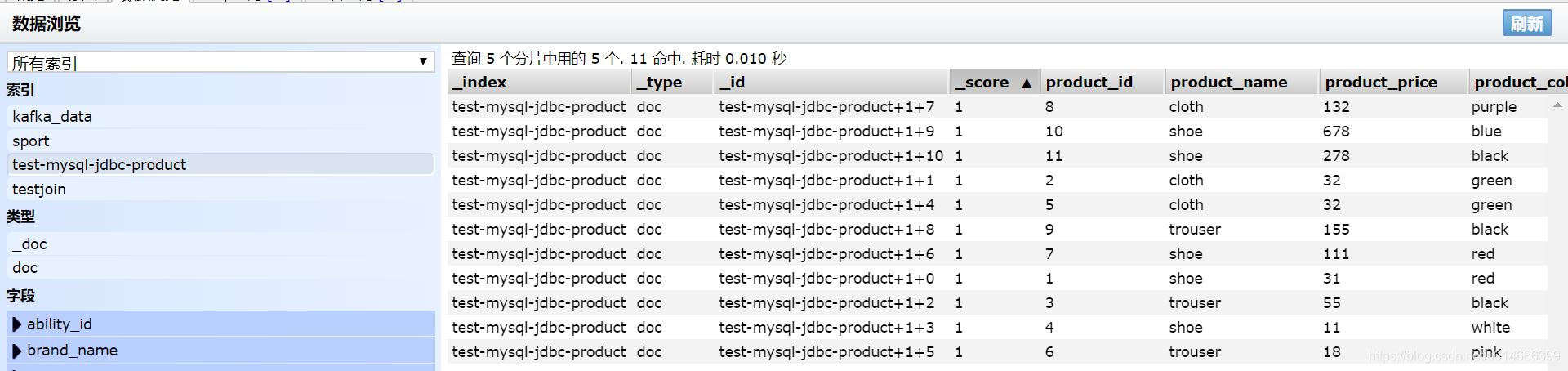
curl -X POST -H 'Content-Type: application/json' -i 'http://x.x.x.x:8083/connectors' --data '{"name":"dump-es",
"config":{
"connector.class":"io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url":"http://x.x.x.x:9200",
"type.name":"doc",
"key.ignore": "true",
"topics":"test-mysql-jdbc-product"
}
}'
如果你的ES不允许自动创建索引,你需要提前创建一个索引,名字就是topics的值,字段的名字要对应好mysql表。connector.class这里要写你的ES插件的地址;connection.url这里写ES的地址;type.name类型的名字;key.ignore如果设置为true,ES里面_id的值会自动生成。
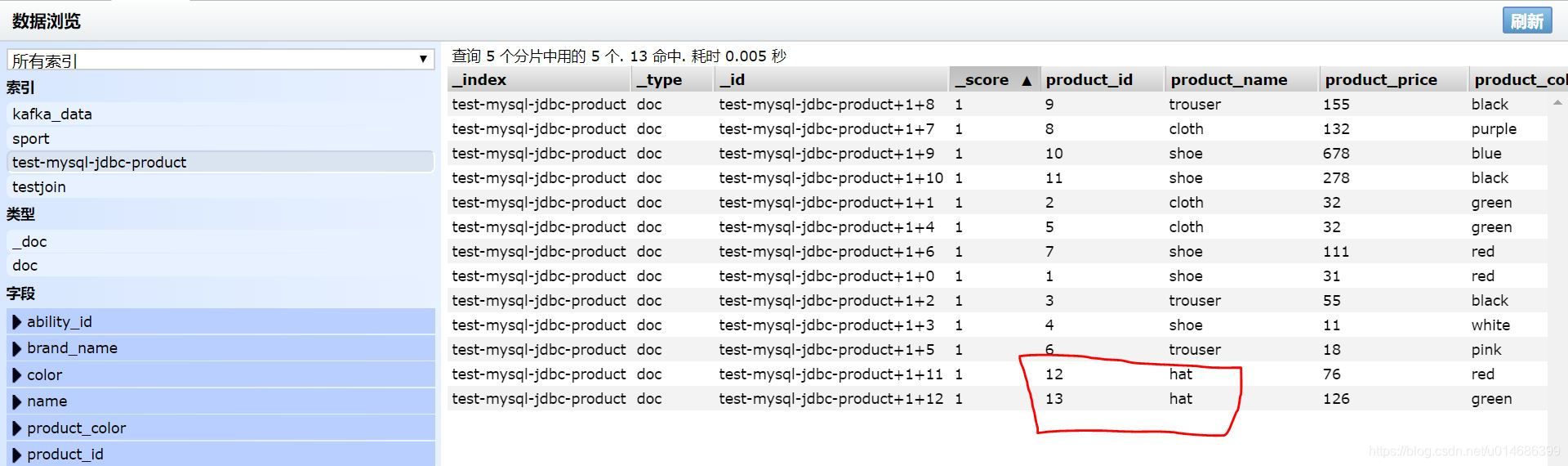
insert product(product_name,product_price, product_color,brand_name) value ("hat",76,"red",1);
insert product(product_name,product_price, product_color,brand_name) value ("hat",126,"green",2);
先写到这里了,有问题进QQ群630300475
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
