社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
任务是用python提取PDF里的表格文件到excel里面去。做为一个 学了一个周python的人来说当然像尝试一下看能不能做到,事实证明是可以的只是可能代码有点烂。。。。。。
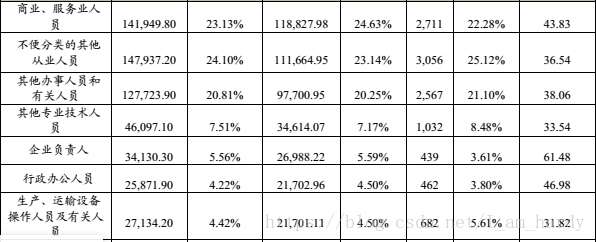
样本大概是这样的
首先网上查一下用python处理pdf文件的方法,感觉处理pdf文件的有好多种方法,各自有各自的特点,印象最深的是转成html文件的pdf2htmlEX,和提取文本的pdfminer,还有最后用的Tabula。分别介绍一下记录。
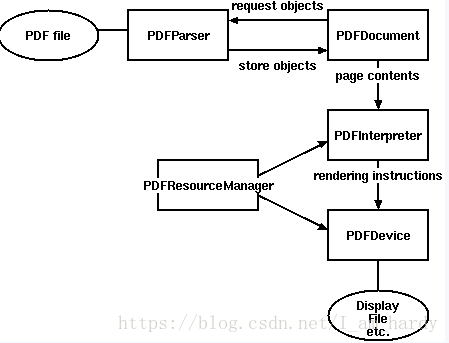
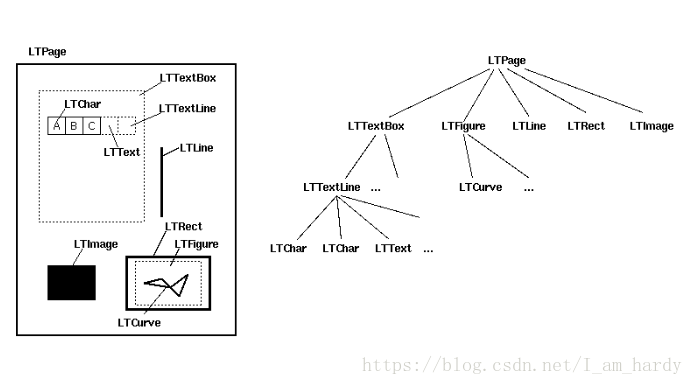
好久之前写了,一些细节忘记了,不过当时注释的很清楚直接上代码,也是怕哪天电脑突然死机代码没了。。。换个地儿存。。。这个模块提取的效率是真的慢。。。。。听说可以调Java的程序提取效率快三倍但是没学Java也就没有去了解,以后还用得到应该可以去了解一下。。。。。。
# -*- coding: utf-8 -*-
import os
import gc
from PyPDF2.pdf import PdfFileReader
from tabula import read_pdf
import pandas as pd
from openpyxl import load_workbook, Workbook
import datetime
def data_process2(dataframe2):
"""
三步:
删除只有一个非空或者全空的列
从第一列开始往后合并直到遇到只有第一列不为空或者全不为空则处理下一步
遇到只有第一行不为空则检查接下来的第三行如果一样情况则接下来三行合并成一行
"""
#此循环处理只有一个非空或者全空列的情况,防止影响下面的处理
k = 0
while True:
if dataframe2.notnull().sum(axis=0)[k] <= 1:
print("%d空列n", k, dataframe2.notnull()[k])
if k+1 == dataframe2.columns.size:
dataframe2 = dataframe2.iloc[0:, :k]
else:
dataframe_left = dataframe2.iloc[0:, :k]
dataframe_right = dataframe2.iloc[0:, k + 1:]
dataframe2 = pd.concat([dataframe_left, dataframe_right], axis=1, ignore_index=True)
k = k-1
if k >= dataframe2.columns.size-1:
break
k = k+1
i = 0
t = 0
print("去掉空列后n", dataframe2)
#空字符代替NaN防止NaN和其他合并时全为空
dataframe2_copy = dataframe2.fillna('', inplace=False)
#此循环处理表头
while True:
if i == 0:
if dataframe2.notnull().sum(axis=1)[0] == dataframe2.columns.size:
break
if dataframe2.notnull().sum(axis=1)[0] == 1 and dataframe2.notnull().iat[0, 0]:
break
i = i + 1
else:
if dataframe2.notnull().sum(axis=1)[i] == dataframe2.columns.size:
t = t+1
break
if dataframe2.notnull().sum(axis=1)[i] == 1 and dataframe2.notnull().iat[i, 0]:
t = t+1
break
dataframe2_copy.iloc[t] = dataframe2_copy.iloc[t] + dataframe2_copy.iloc[i]
i = i+1
if i >= len(dataframe2):
t = t + 1
break
print("处理表头中n", dataframe2_copy)
#去掉空行,并且重新索引
dataframe2_copy.dropna(axis=0, how='all', inplace=True)
dataframe2_copy = dataframe2_copy.reset_index(drop=True)
#次循环处理表里的数据
while i < len(dataframe2):
if i+2 >= len(dataframe2):
for p in range(len(dataframe2)-i):
dataframe2_copy.iloc[t] = dataframe2_copy.iloc[i+p]
t = t+1
break
elif dataframe2.notnull().sum(axis=1)[i] == 1 and dataframe2.notnull().iat[i, 0]:
if dataframe2.notnull().sum(axis=1)[i+2] == 1 and dataframe2.notnull().iat[i+2, 0]:
dataframe2_copy.iloc[t] = dataframe2_copy.iloc[i] + dataframe2_copy.iloc[i+1] + dataframe2_copy.iloc[i+2]
i = i+3
elif i+4 < len(dataframe2):
if dataframe2.notnull().sum(axis=1)[i + 1] == 1 and dataframe2.notnull().sum(axis=1)[i + 3] == 1 and dataframe2.notnull().sum(axis=1)[i + 4] == 1 and dataframe2.notnull().iat[i+1, 0] and dataframe2.notnull().iat[i+3, 0] and dataframe2.notnull().iat[i+4, 0]:
dataframe2_copy.iloc[t] = dataframe2_copy.iloc[i] + dataframe2_copy.iloc[i + 1] + dataframe2_copy.iloc[i + 2] + dataframe2_copy.iloc[i + 3] + dataframe2_copy.iloc[i + 4]
i = i + 5
else:
dataframe2_copy.iloc[t] = dataframe2_copy.iloc[i]
i = i + 1
else:
dataframe2_copy.iloc[t] = dataframe2_copy.iloc[i]
i = i + 1
else:
dataframe2_copy.iloc[t] = dataframe2_copy.iloc[i]
i = i+1
t = t+1
print("一个表的数据n",dataframe2_copy)
return dataframe2_copy.iloc[:t]
def data_process1(dataframes):
"""
根据两个空格拆分列数据合并
适用于数据均为str类型表格
如果非str型合并后为空数据丢失
"""
dataframes.fillna('', inplace=True)
print("处理前数据:n", dataframes)
n = 0
while True:
try:
dataframes[n].str.split(' ', expand=True)#一列全是非str pass
dataframes[n] = dataframes[n].astype('str')#处理有一部分为非str情况,防止数据丢失
over_data = dataframes[n].str.split(' ', expand=True)
over_data.fillna('', inplace=True)
except:
print("遇到非str型的列 pass")
n = n+1
if n >= dataframes.columns.size:
break
else:
continue
print("重叠的列:n", over_data)
if n-1 < 0:
dataframe_right = dataframes.iloc[0:, n + 1:]
dataframes = pd.concat([over_data, dataframe_right], axis=1, ignore_index=True)
elif n+1 > dataframes.columns.size:
dataframe_left = dataframes.iloc[0:, :n]
dataframes = pd.concat([dataframe_left, over_data], axis=1, ignore_index=True)
else:
dataframe_left = dataframes.iloc[0:, :n]
dataframe_right = dataframes.iloc[0:, n+1:]
dataframes = pd.concat([dataframe_left, over_data, dataframe_right], axis=1, ignore_index=True)
n = n + over_data.columns.size
if n >= dataframes.columns.size:
break
print("处理后数据n:", dataframes)
return dataframes
def getCashflowAggregation(dataframe1):
pass
def pdf_to_xlsx(folder):
"""
提取文件夹的PDF里表格数据
对数据做初步整理
对每个dataframe识别提取想要的数据保存到相应的sheet里,
输出同名xlsx格式文件
"""
files = os.listdir(folder)
#遍历文件夹,找出PDF文件
pdfFile = [f for f in files if f.endswith(".pdf")]
for pdfFiles in pdfFile:
#建立一个和PDF同名的xlsx文件
pdfPath = os.path.join(folder, pdfFiles)
xlsPath = pdfPath[:-3] + "xlsx"
#建立Workbook然后和所要保存的数据表格连接,之后每次保存都会保存到不同的Sheet中
Workbook(xlsPath)
book = Workbook()
book.save(filename=xlsPath)
#获取PDF的页数
pdf = PdfFileReader(open(pdfPath, "rb"))
page_counts = pdf.getNumPages()
dataframe2 = pd.DataFrame()
#遍历PDF每一页,提取出表格数据
for page in range(1, page_counts+1):
try:
pf = read_pdf(pdfPath, encoding='gbk', multiple_tables=True,pages = page)
if len(pf) != 0:
for t in range(len(pf)):
dataframe1 = pf[t]
dataframe1 = data_process2(dataframe1)#处理表头
dataframe1 = data_process1(dataframe1)#按空格拆分合并项
#CashflowAggregation = getCashflowAggregation(dataframe1)
#列数相同的表格合并,并且删除重复项并保存
if dataframe2.empty:
dataframe2 = dataframe1
elif dataframe1.columns.size == dataframe2.columns.size:
dataframe2 = pd.concat([dataframe2,dataframe1],ignore_index=True)
#删除重复项会影响池分布的匹配提取,但是可以很好的处理静动态池和现金流归集
#dataframe2.drop_duplicates(keep="first", inplace=True)#在原来的数据里删除重复项
print(dataframe2)
else:
print("列数:", dataframe1.columns.size)
print(dataframe2)
#保存在不同的工作簿
writer = pd.ExcelWriter(xlsPath, engin='openpyxl')
book = load_workbook(writer.path)
writer.book = book
dataframe2.to_excel(writer, sheet_name='shet')
writer.close()
dataframe2 = dataframe1
del(pf)
gc.collect()
except:
gc.collect()
print("Error Pass")
continue
#保存最后的数据表格到另一个工作表里
writer = pd.ExcelWriter(xlsPath, engin='openpyxl')
book = load_workbook(writer.path)
writer.book = book
dataframe2.to_excel(writer, sheet_name='shet')
writer.close()
star_time = datetime.datetime.now()
pdf_to_xlsx("D:\2018暑假\新建文件夹")
stop_time = datetime.datetime.now()
print("程序运行时间:", stop_time-star_time)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!